






高速高精度成像:相控阵CT与工业CT重建算法的硬件加速方案
时间:2026-02-25 21:48:01
来源:UltraLAB图形工作站方案网站
人气:3786
作者:管理员
——当全聚焦方法遭遇十亿级像素投影,什么样的异构算力架构能支撑下一代无损检测的实时 revolution?
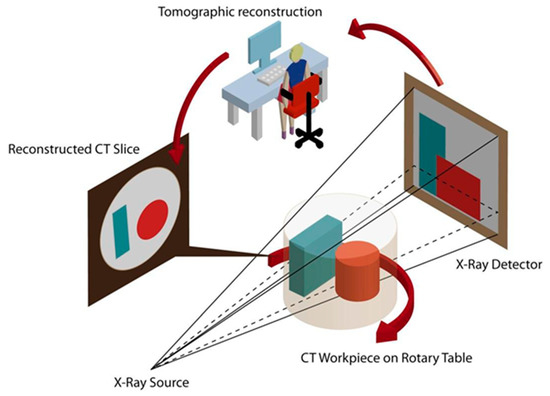
引言:从"拍片等半天"到"即扫即现",算力是隐形拐点
在航空航天复合材料的无损检测车间,工程师刚完成对一个碳纤维机翼梁的相控阵超声扫描。屏幕上,全聚焦方法(TFM)生成的三维缺陷云图随探头移动实时刷新,0.2mm的分层缺陷在亚毫米级体素中清晰可辨。而在隔壁的工业CT实验室,高分辨率显微CT(μCT)正在重建一个增材制造(3D打印)钛合金叶片的内部孔隙网络——2048×2048×2048的体数据,从投影采集到体绘制(Volume Rendering)出图,总耗时不到15分钟。
这两个场景代表了高端无损检测(NDT)的技术巅峰:前者是相控阵超声(PAUT)与合成孔径聚焦技术(SAFT/TFM)融合形成的"超声CT"体系,后者是工业X射线CT向纳米级分辨率进军的精密成像。而支撑这一切从"实验室玩具"变为"产线标配"的核心驱动力,并非算法理论的突破(FBP、ART、OS-SART等重建算法已成熟多年),而是异构计算硬件(GPU/FPGA/多核CPU)与专用存储架构的系统性工程。
作为深耕科学计算硬件领域的UltraLAB,我们在服务中国航发商发、中科院金属所、西门子能源等高端制造用户过程中发现:相控阵实时成像与工业CT高精度重建,虽然物理原理迥异(超声波 vs X射线),却在计算层面面临着相似的"存储墙"与"并行效率"困境。本文将深度解构这两类成像技术的算法特征,并给出从边缘计算到数据中心的硬件加速方案。
一、相控阵超声CT:全聚焦方法(TFM)的实时性困局
1.1 从延时叠加到波动方程成像:算力需求的质变
传统相控阵超声检测依赖电子扫查(Electronic Scanning)和扇形扫查(Sectorial Scanning),但现代无损检测要求的全聚焦方法(Total Focusing Method, TFM)本质上是一种合成孔径成像:
I(x,z)=∑i=1Ntx∑j=1Nrxsij(tij(x,z))⋅wij
其中 sij 为第 i 个发射阵元、第 j 个接收阵元采集的A扫信号,tij 为声程时间。对于 64 阵元的相控阵探头,全矩阵捕获(FMC)数据量为 64×64×Nsamples 。若进行三维体成像(2D阵列探头),计算复杂度呈 O(N4) 增长。
实时性瓶颈:
-
在线检测要求:产线节拍通常要求 >30fps 的成像帧率,这意味着从原始A扫数据到TFM图像的延迟必须 <33ms。
-
插值与相干因子:高阶成像(如PCI相干相位成像、自适应TFM)需在GPU上执行双线性插值、希尔伯特变换、空间相干系数计算。
-
数据吞吐:64阵元、100MHz采样率、12bit精度,原始数据率已达 >1GB/s。
CPU的无力:传统CPU串行处理FMC数据,生成一张2048×1024像素的TFM图像需数秒,完全无法满足产线速度。这催生了基于 FPGA前置预处理 + GPU并行反演 的异构架构。
1.2 相控阵CT的硬件加速特征
| 计算环节 | 算法特征 | 硬件需求 | 加速方案 |
|---|---|---|---|
| 波束形成(Beamforming) | 延时求和、动态聚焦 | 低延迟、确定性时序 | FPGA(Zynq UltraScale+) |
| 信号预处理 | 滤波、检波、包络提取 | 高内存带宽、SIMD | GPU CUDA Core(Tensor Core用于AI降噪) |
| 图像重建(TFM/SAFT) | 双求和、索引不规则 | 高并行度、大显存 | NVIDIA RTX A6000(48GB显存) |
| 后处理与可视化 | 体绘制、缺陷识别 | 实时渲染能力 | OpenGL/Vulkan硬件加速 |
二、工业CT重建:从解析法到迭代法的算力跃迁
2.1 解析重建(FBP/FDK)的并行特征
工业CT的主流重建算法仍是滤波反投影(FBP)及其三维扩展FDK算法(Feldkamp-Davis-Kress)。其计算流程为:
-
预处理:对数变换、坏点校正、射线硬化校正(CPU密集型)
-
滤波: ramp filter 或 Shepp-Logan 滤波(FFT加速,GPU友好)
-
反投影(Backprojection):将滤波后的投影数据沿射线方向累加到体素——这是计算瓶颈,占整体时间的70-90%。
数学上,反投影是高度并行的"射线-体素"映射操作,天然适合GPU的SIMT架构。但高精度CT的内存墙问题极为严峻:
-
高分辨率平板探测器(4096×4096像素),3600个角度投影,原始数据量:>240GB(单精度浮点)。
-
重建体数据(2048³体素):32GB。
-
若采用迭代重建(SIRT/SART),需多次正投影(Forward Projection)与反投影交替,中间变量需常驻显存。
2.2 迭代重建与低剂量成像:计算密集型的崛起
随着工业CT追求低剂量高分辨(减少X射线管负荷、降低样品辐射损伤),解析FBP因噪声敏感逐渐被统计迭代重建(SIR)取代:
-
SART/SIRT算法:涉及大规模稀疏矩阵乘法,收敛需50-200次迭代。
-
正则化约束:TV全变分最小化、非局部均值(NLM)去噪,需稀疏矩阵-向量乘(SpMV)。
-
GPU显存瓶颈:2048³体素的SIRT重建,系统矩阵即使采用稀疏存储也远超单卡显存(48GB),必须采用多GPU并行或CPU-GPU协同出核计算(Out-of-Core)。
三、硬件加速方案:UltraLAB的异构计算架构
针对上述两类成像技术的计算特征,UltraLAB提出"数据流优化"的硬件加速理念:不是简单的"CPU+GPU堆砌",而是根据数据局部性(Temporal/Spatial Locality)设计内存层级与计算单元配比。
3.1 方案A:相控阵实时成像工作站(Edge Computing)
目标场景:产线集成、机器人搭载超声检测、水浸C扫描系统
UltraLAB PAUT-TFM 实时成像工作站:
-
FPGA加速卡:Xilinx Alveo U50或自研Zynq载板
-
实现100MHz采样率的实时波束形成,将1GB/s原始A扫数据流预处理后降维至100MB/s特征数据
-
确定性延迟 <10μs,满足闭环控制需求
-
-
GPU计算节点:NVIDIA RTX 4090(24GB)或 RTX A6000(48GB)
-
利用CUDA Core执行TFM的延时叠加计算
-
对于64×64阵元、2048×1024成像区域,实现>50fps实时成像
-
-
CPU:Intel Core i9-14900K(高主频应对串行预处理)
-
存储:2TB NVMe Gen4(RAID 0,用于原始数据缓存),确保FMC数据不丢帧
技术亮点:
-
GPUDirect RDMA:FPGA采集卡直接通过PCIe P2P传输数据至GPU显存,绕过CPU内存,降低延迟30%
-
统一内存架构(Unified Memory):在A6000上启用Managed Memory,自动处理超显存大模型分页
3.2 方案B:高精度工业CT重建服务器(Reconstruction Farm)
目标场景:纳米CT(μCT)、增材制造缺陷分析、锂电池内部结构成像
UltraLAB CT-Rec 重建服务器:
-
多GPU并行架构:4× NVIDIA RTX A6000(48GB×4=192GB显存)
-
采用NVLink Bridge连接(若使用A100则通过NVSwitch),实现显存池化
-
使用ASTRA Toolbox或RTK(Reconstruction Toolkit)进行多GPU FDK/SIRT
-
-
CPU:AMD Ryzen Threadripper PRO 7995WX(96核)
-
负责I/O密集型预处理(投影数据读取、几何校正、坏点修复)
-
八通道DDR5-4800提供~400GB/s内存带宽, feeding数据至GPU
-
-
存储系统:
-
热层:4×4TB NVMe U.2企业级SSD(RAID 0,读写速度>12GB/s),存放原始投影数据
-
温层:8×18TB SAS HDD(RAID 6),长期存档重建结果
-
内存盘:将512GB系统内存划分为RAM Disk,作为迭代重建的临时交换区,消除SSD磨损
-
-
网络:双端口100GbE,支持从CT扫描设备高速接收投影数据流
性能基准:
-
对于2048×2048×2048体素、3600投影的FDK重建,单GPU需~45分钟,4×A6000并行可缩短至12分钟。
-
若采用SIRT迭代重建(100次迭代),利用多GPU分担体数据子块,可在2小时内完成,而传统CPU方案需~20小时。
3.3 方案C:混合架构集群(相控阵+CT融合检测中心)
目标场景:国家质检中心、大型研究院所的多模态无损检测平台
当用户需要同时处理相控阵超声的实时流数据与工业CT的海量体数据时,UltraLAB提供异构计算集群:
-
登录/调度节点:UltraLAB EX650i(管理作业提交、数据归档)
-
GPU计算节点(8节点):每节点4×A100 80GB,专责CT迭代重建
-
FPGA预处理节点(4节点):配备Alveo U280,专责相控阵数据前端处理
-
存储节点:并行文件系统(BeeGFS/Lustre),聚合带宽>100GB/s
-
高速互联:InfiniBand HDR(200Gbps),确保投影数据从存储节点流向GPU节点无阻塞
四、关键硬件选型深度解析
4.1 GPU选型:游戏卡 vs 专业卡 vs 计算卡
| 型号 | 显存 | 适用场景 | UltraLAB建议 |
|---|---|---|---|
| RTX 4090 | 24GB GDDR6X | 相控阵实时成像、中小规模CT(1024³以下) | 性价比首选,但无ECC显存,长时间迭代重建存在位翻转风险 |
| RTX A6000 | 48GB GDDR6 ECC | 大体积CT重建(2048³)、多模态数据融合 | 均衡之选,ECC显存保障数值稳定性,支持NVLink |
| A100 80GB | 80GB HBM2e | 超大规模迭代重建(4096³)、AI辅助成像 | 极致性能,Tensor Core加速正则化计算,但成本高昂 |
| L40S | 48GB GDDR6 ECC | 数据中心级连续负载 | 替代A6000,Ada架构,Transformer Engine加速 |
关键提示:工业CT重建对显存容量的敏感度远高于CUDA Core数量。一个2048³的单精度浮点体数据占用32GB,加上投影数据和中间变量,48GB显存是工业级应用的入门门槛。
4.2 存储架构:消除I/O瓶颈
CT重建是典型的"读密集型"应用:
-
FDK重建需反复读取投影数据(3600次全量读取)
-
迭代重建需频繁读写体数据
UltraLAB存储优化策略:
-
投影数据预加载:在重建前将原始数据从HDD批量加载至NVMe SSD,或直接将近期数据缓存于内存。
-
分块重建(Chunked Reconstruction):将2048³体积分割为512³子块,逐块加载至GPU,降低显存需求,但需权衡块间通信开销。
-
写回优化:重建结果直接写入内存映射文件(Memory-Mapped File),避免用户空间到内核空间的数据拷贝。
4.3 CPU的"被忽视价值":预处理与后处理
尽管GPU主导了重建加速,但CPU在以下环节至关重要:
-
几何校正:探测器歪斜、旋转中心偏移的校正涉及不规则内存访问,CPU更灵活。
-
环形伪影去除:小波变换或频域滤波,需高内存带宽。
-
体数据可视化:Marching Cubes等值面提取、光线投射(Ray Casting)渲染。
因此,UltraLAB方案坚持"高频多核CPU+大容量内存"的底座配置,避免"头重脚轻"(GPU强而CPU弱导致数据饥饿)。
五、软件生态与硬件协同优化
硬件加速的效果取决于软件层面对异构架构的利用:
对于相控阵成像:
-
自定义CUDA Kernel:针对TFM的延时计算开发专用Kernel,利用Texture Memory缓存A扫数据,提高随机读取效率。
-
TensorRT加速:若集成AI缺陷识别(如UNet分割),将PyTorch模型转换为TensorRT引擎,利用FP16精度在RTX显卡上实时推理。
对于工业CT重建:
-
ASTRA Toolbox:支持多GPU并行,需合理设置
--gpu_index与--split参数。 -
NVIDIA Clara Holoscan:面向医疗/工业成像的 streaming processing 框架,支持从数据采集到AI推理的流水线加速。
UltraLAB在交付系统时,提供预编译优化的重建环境,包括:
-
针对Intel MKL或AOCC编译器优化的CPU端反投影代码
-
预配置的CUDA环境(cuFFT、cuBLAS、Thrust库)
-
容器化部署(Docker/Singularity),确保不同用户环境的可复现性
结语:算力密度决定成像精度边界
从相控阵超声的微米级缺陷定位,到工业CT的纳米级孔隙解析,无损检测技术正向着"更高分辨率、更快检测速度、更大数据体量"的三重极限进发。在这一进程中,算法理论的演进已相对平缓,而硬件加速技术的创新——从FPGA的纳秒级延迟控制,到GPU的万亿次浮点运算,再到NVMe存储的微秒级访问——正在重新定义成像系统的工程边界。
UltraLAB深刻理解:对于科研单位的工程师而言,一套优秀的成像计算平台不仅是"跑得快",更要"跑得稳"(ECC校验、冗余电源)、"用得爽"(低延迟交互、可视化流畅)、"护得住"(数据安全、长期技术支持)。
无论是需要在产线上实现实时TFM成像的超声检测工程师,还是面对TB级CT投影数据亟待重建的材料科学家,UltraLAB都能提供从边缘计算工作站到数据中心级集群的全谱系硬件加速方案。我们不仅售卖硬件,更提供基于具体算法特征(FBP vs SIRT,TFM vs PCI)的性能调优服务,确保每一分算力投资都转化为清晰的图像细节与检测效率。
在看不见的声波与X射线世界里,让我们用看得见的算力,照亮材料内部的每一个微观缺陷。
关于UltraLAB工业成像解决方案
UltraLAB专注于科学计算与工程可视化硬件定制,为无损检测、生物医学成像、材料表征等领域提供高性能计算平台。我们的技术团队精通CUDA并行编程、FPGA逻辑开发及高速存储系统设计,致力于打通从"数据采集"到"智能诊断"的算力链路。
获取《工业CT重建硬件配置指南》或预约相控阵实时成像系统演示,请联系UltraLAB技术顾问。


