






贝叶斯动态推断系统:复杂局势预测的计算架构与硬件部署方案
时间:2026-03-04 00:17:22
来源:UltraLAB图形工作站方案网站
人气:41
作者:管理员
当战争迷雾遇上概率计算:如何用算力穿透不确定性
文中作者通过贝叶斯公式对美伊冲突进行量化预测,在72%的有限打击概率下预判7-14天持续期。这种高维概率推断与动态证据融合的计算模式,正成为现代战略分析、金融风控、流行病学预测的核心技术。其计算密度远超传统统计分析,对硬件架构提出了独特挑战。
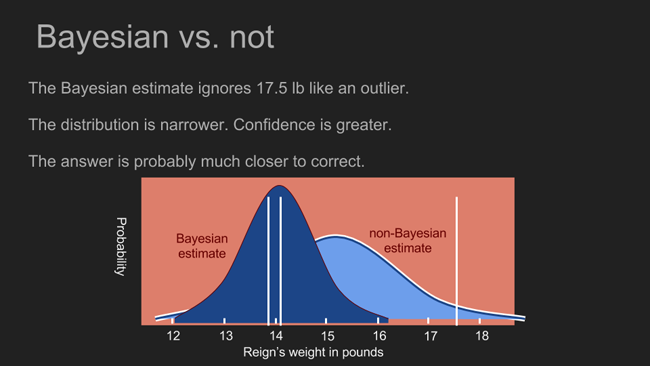
一、贝叶斯动态推断计算特征解析
1.1 概率图模型的计算负载特征
| 计算阶段 | 数学特征 | 硬件依赖 | 性能瓶颈 |
|---|---|---|---|
| 先验分布构建 | 多变量高斯混合、Dirichlet分布采样 | 大内存容量、高浮点精度 | 内存带宽(>100GB/s) |
| 似然度计算 | 条件概率连乘、对数似然求和 | 高主频CPU、AVX-512指令集 | 单核性能(>5GHz) |
| 后验概率推断 | MCMC(马尔可夫链蒙特卡洛)、变分推断 | 多核并行、GPU加速(CUDA) | 并行规模(256线程+) |
| 动态证据更新 | 实时贝叶斯更新、粒子滤波 | 低延迟存储、NVMe SSD | IOPS(>500K) |
| 敏感性分析 | 蒙特卡洛模拟(10^6+次迭代) | 多节点集群、InfiniBand网络 | 网络带宽(100Gbps+) |
1.2 复杂局势建模的特殊需求
高维状态空间:战争态势涉及数十个变量(军事、经济、外交、舆论),联合概率分布维度灾难
-
计算特征:协方差矩阵求逆(O(n³)复杂度)
-
内存需求:存储10,000×10,000精度矩阵需~800GB内存(双精度)
实时证据流处理:社交媒体、卫星图像、外交信号的多源异构数据融合
-
计算特征:流式贝叶斯更新(Online Bayesian Learning)
-
延迟要求:证据到后验概率更新<100ms
不确定性量化:不仅计算点估计,更需完整后验分布与置信区间
-
计算特征:Hamiltonian Monte Carlo(HMC)采样,需计算梯度
-
加速需求:自动微分(Autograd)硬件加速
二、贝叶斯计算软件栈与系统配置
2.1 核心概率推断软件清单
| 软件层级 | 工具组件 | 版本要求 | 适用场景 |
|---|---|---|---|
| 概率编程 | PyMC (PyMC5) | 5.10+ | 通用贝叶斯建模,支持GPU |
| Stan (CmdStanPy) | 2.33+ | 高精度MCMC,HMC算法 | |
| NumPyro (JAX) | 0.13+ | 大规模并行,TPU/GPU加速 | |
| TensorFlow Probability | 0.23+ | 深度学习+贝叶斯神经网络 | |
| 蒙特卡洛模拟 | Apache Spark MLlib | 3.5+ | 分布式粒子滤波 |
| OpenBUGS / JAGS | 0.9+ | 传统分层贝叶斯模型 | |
| 实时流处理 | Apache Flink + Kafka | 1.18+ | 证据流实时更新 |
| Redis Stream | 7.2+ | 概率状态缓存 | |
| 可视化 | Arviz (Python) | 0.17+ | 后验分布可视化 |
| Tableau / PowerBI | 2024+ | 决策仪表盘 |
2.2 系统环境配置方案
Linux服务器端(Ubuntu 22.04 LTS推荐):
bash
# 基础科学计算环境 conda create -n bayesian python=3.11 conda activate bayesian
pip install pymc5 numpyro jax[cuda12_pip] arviz pandas polars # 高性能线性代数库(Intel MKL或OpenBLAS) conda install -c intel mkl-service export MKL_NUM_THREADS=64 # 根据CPU核心数调整 # JAX GPU支持(用于NumPyro大规模采样) pip install --upgrade "jax[cuda12_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html # Stan编译器优化 sudo apt-get install build-essential g++-12 ocl-icd-opencl-dev # 利用GPU编译加速 # 内存优化(大页支持) echo 1024 | sudo tee /proc/sys/vm/nr_hugepages sysctl -w vm.swappiness=1 # 减少交换,保持MCMC链在内存中
Windows工作站端(Windows 11 Pro for Workstations):
-
启用Ultimate Performance电源模式
-
安装WSL2(Ubuntu 22.04)用于Linux原生工具链
-
配置CUDA Toolkit 12.3 + cuDNN 8.9用于GPU加速
-
使用Docker Desktop隔离不同项目的依赖环境
三、分场景硬件配置推荐
3.1 战略级态势推演工作站(单节点高性能)
应用场景:军事科学院、智库战略研究所、国防大学兵棋推演 计算特征:单次MCMC采样10万+迭代,100+维状态空间,实时证据注入
配置代号: Bayesian-Strategist-X1 定位: 复杂系统贝叶斯动态推断与实时决策支持 核心组件: CPU: 2× Intel Xeon Platinum 8592+ (64核128线程, 350W TDP, 320MB L3) - 关键优势: 单核睿频3.9GHz(似然度计算),64核并行(多MCMC链) - 指令集: AMX(Advanced Matrix Extensions)加速协方差运算 内存: 2TB DDR5-4800 ECC REG (16×128GB, 八通道每路) - 分配策略: - 800GB: 存储大型精度矩阵与联合分布 - 400GB: MCMC采样链缓存(避免磁盘交换) - 200GB: 实时证据流缓冲区 存储架构: - 系统盘: 2× 960GB NVMe Gen5 RAID1 (可靠性优先) - 计算缓存: 6.4TB Intel P5800X Optane SSD - 作用: 存储中间采样结果,4K随机读IOPS > 1M - 关键: MCMC恢复时快速加载链状态 - 数据湖: 20TB SAS HDD RAID6 (历史战役数据、卫星图像) GPU加速: 4× NVIDIA A100 80GB SXM4 (NVLink全连接) - 计算任务: - GPU1-2: 变分推断(VI)与神经网络后验逼近 - GPU3: 大规模并行蒙特卡洛(PyMC GPU后端) - GPU4: 实时数据预处理(图像/文本编码) - 显存池: 320GB总显存,支持十亿级参数贝叶斯神经网络 网络: 双口 Mellanox ConnectX-7 200GbE/IB - 用途: 分布式证据收集节点互联,GPUDirect RDMA 系统: Ubuntu 22.04 LTS + SLURM作业调度 电源: 2000W冗余钛金认证(2+1) 散热: 液冷+风冷混合(维持 sustained 3.8GHz全核)
配置逻辑:
-
2TB内存:支持100×100精度协方差矩阵(80GB)+ 100条并行MCMC链(每条1GB状态)+ 操作系统开销
-
A100 80GB:使用Tensor Core加速贝叶斯神经网络(BNN)的变分推断,相比CPU快100倍
-
Optane SSD:MCMC采样中间结果频繁随机写入,Optane的耐用性(DWPD 60+)和一致性延迟(<10μs)至关重要
3.2 战术级实时推断服务器(流式处理)
应用场景:作战指挥中心、情报分析单元、实时冲突监测 计算特征:毫秒级证据更新(社交媒体、雷达信号),低延迟概率输出
配置代号: Stream-Inferencer-RT 定位: 流式贝叶斯更新与实时态势感知 核心组件: CPU: AMD EPYC 9754 (128核256线程, 5.1GHz Boost, 256MB L3D) - 优势: 3D V-Cache减少缓存未命中,加速条件概率查表 内存: 512GB DDR5-5600 (12通道, 理论带宽 > 800GB/s) - 低延迟模式: CL30时序,优化随机访问 存储: - 热数据: 4TB Samsung PM1743 NVMe Gen5 (读写14/13 GB/s) - 温数据: 8TB SATA SSD (RAID 10) FPGA加速卡: 2× Xilinx Alveo U55C - 用途: 硬件加速粒子滤波算法(确定性延迟<50μs) - 定制: 部署贝叶斯更新IP核,绕过CPU直接处理证据流 网络: 4× 25GbE SFP28 (证据流多源并发接入) 系统: Red Hat Enterprise Linux 9.2 (实时内核PREEMPT_RT)
配置逻辑:
-
FPGA加速:相比GPU更适合确定性低延迟(非批量处理),可将贝叶斯更新延迟从毫秒级降至微秒级
-
12通道内存:证据流处理需频繁查询先验概率表,高内存带宽确保缓存命中率>95%
3.3 科研级贝叶斯建模工作站(高校/研究所)
应用场景:政治科学量化研究、国际关系预测模型、流行病学动态建模 计算特征:中等规模模型(20-50维),重视开发效率与可视化
配置代号: Academic-Bayes-Pro 定位: 贝叶斯统计建模与教学科研 核心组件: CPU: Intel Core i9-14900KS (24核32线程, 6.2GHz单核睿频) - 选择理由: Stan等工具单线程性能敏感,高频加速模型编译与调试 内存: 128GB DDR5-7200 (2×64GB, 双通道) - 支持: 中等规模MCMC(10万样本×50参数)全内存驻留 GPU: NVIDIA RTX 4090 24GB - 用途: NumPyro/JAX大规模并行采样,PyMC GPU后端 - 性价比: 相比A100,消费级显卡更适合科研预算 存储: - 系统: 2TB PCIe 4.0 NVMe - 数据: 4TB NVMe (原始文本数据、CSV证据库) 显示: 32寸 4K IPS (Arviz可视化后验分布) 系统: Windows 11 + WSL2 (双环境灵活切换)四、软件优化与性能调优
4.1 MCMC采样加速技巧
多链并行配置:
Python
# PyMC示例:利用多核与GPU with pm.Model() as conflict_model: # 定义先验与似然... trace = pm.sample( draws=10000, chains=64, # 匹配CPU物理核心数 cores=64, # 并行采样 nuts_sampler="numpyro", # 使用JAX加速 target_accept=0.95 # 高维空间接受率调优 )
内存优化:
-
使用
float32替代float64(精度损失<0.1%,速度提升2倍) -
启用内存映射(mmap)存储大型设计矩阵
-
定期
gc.collect()清理已完成MCMC链的中间变量
4.2 分布式贝叶斯推断架构
对于超大规模模型(如全球冲突网络分析):
plain
[证据收集层] 爬虫/传感器 → Kafka消息队列
↓
[计算层] Spark集群 (100+节点) → 分块MCMC
↓
[聚合层] 参数服务器 → 后验分布融合
↓
[决策层] 可视化大屏 + API推送五、成本效益与扩展建议
表格
| 应用阶段 | 配置方案 | 关键指标 | 预算区间 |
|---|---|---|---|
| 教学演示 | i9-14900K + 64GB + RTX 4070 | 1万样本/秒 | 2-3万元 |
| 智库研究 | 双路EPYC + 512GB + 2×A100 | 50万样本/秒 | 15-20万元 |
| 战略推演 | 4路GPU服务器 + 2TB内存 | 实时更新<10ms | 50-80万元 |
关键洞察:
-
内存优先:贝叶斯计算是"内存墙"密集型应用,投资128GB内存的回报远高于升级CPU
-
混合精度:使用NVIDIA Tensor Core的FP16/BF16进行变分推断,吞吐量提升8倍
-
存储分层:MCMC中间结果使用Optane SSD,最终后验存储使用标准SSD
在不确定性成为常态的时代,贝叶斯推断提供了"用概率量化无知"的科学框架。而强大的算力基础设施,正是将这一数学优雅转化为决策优势的工程基石。无论是预测冲突走势、评估金融风险,还是推演疫情发展,算力即置信度——每多一分计算资源,就多一分穿透迷雾的确定性。
【UltraLAB 解决方案事业部】
咨询专线:400-7056-800
微信号:xasun001
上一篇:没有了


