






超频、PCIe4.0-最新最全深度学习工作站方案2021v2
目录
1 提升深度学习算力的最新硬件方案
2 深度学习选择GPU-性能指标最新排序
3 UltraLAB深度学习工作站新机型介绍
4 UltraLAB 深度学习工作站基准配置方案2021v2
4.1 GA300i深度学习工作站配置推荐(2块GPU方案,超值型)
4.2 GT410P深度学习工作站配置推荐(最大5块GPU方案,高性能型)
4.3 GX650M深度学习工作站配置推荐(最大6块GPU方案,完美极致型)
最新xeon三代+PCIe 4.0架构-深度学习训练、AI智能、神经元计算基准配置推荐2021v2
最新AMD锐龙Pro+PCIe 4.0架构-深度学习训练、AI智能、神经元计算基准配置推荐2021v3
一.提升深度学习性能的最新硬件
随着深度学习、人工智能、大数据AI分析等应用深入,对图形工作站的性能要求越来越高,深度学习主流框架Pytorch、Tensorflow等,在GPU训练神经网络性能指标---训练吞吐量,如何通过模型更快地运行数据集,需要调用更多GPU并行训练,如何提升深度学习算力的硬件性能,关键硬件如下:
|
No |
关键硬件 |
主要任务 |
解决方案 |
|
1 |
硬盘读取速度 |
数据从硬盘读取到内存,并做一些预处理 |
PCIe 4.0 SSD卡 |
|
2 |
PCIe传输速度 |
内存中的数据通过PCIe总线传输到GPU显存 |
PCIe 4.0 x16接口 |
|
3 |
CPU频率 |
从内存中取出一批数据,转化为numpy array,并作数据预处理/增强操作,如翻转、平移、颜色变换等。处理完毕后送回内存 |
数据预处理是CPU单核计算,cpu频率至关重要 |
|
4 |
内存 |
数据从硬盘读取到内存,GPU计算好结果返回到内存 |
内存容量、带宽 |
|
5 |
GPU卡 |
计算机视觉(CV)、自然语言处理(NLP)、文本到语音 (TTS) 等的 GPU 训练速度 每秒处理样本()的数量 |
单卡的CUDA FP32、Tensor FP16指标越高越好 多卡并行数量越大越好 |
二.深度学习选择GPU-最新性能指标排序
(GPU型号性能对比表,按单精度FP32排序)
|
No |
型号 |
卡数 |
CUDA核数 |
单精度FP32 Tfops |
张量计算FP16 (Tfops) |
显存带宽GBs |
显存 合计GB |
备注 |
|
1 |
A6000 |
7块 |
75264 |
280 |
2184 |
768 |
336 |
超越DGX-2 |
|
2 |
RTX3090 |
7块 |
73472 |
249 |
1995 |
936 |
168 |
超越DGX-2 |
|
3 |
A6000 |
6块 |
64512 |
240 |
1872 |
768 |
288 |
超越DGX-2 |
|
4 |
RTX3080 |
8块 |
69632 |
238 |
1904 |
760 |
80 |
超9*2080ti |
|
5 |
Tesla V100 |
16块 |
81920 |
238 |
1760 |
653 |
192 |
DGX-2 |
|
6 |
RTX3090 |
6块 |
62976 |
213 |
1710 |
936 |
144 |
接近DGX-2 |
|
6 |
A6000 |
5块 |
53760 |
200 |
1560 |
768 |
240 |
全能高速 |
|
7 |
RTX3080 |
6块 |
52224 |
179 |
1428 |
760 |
60 |
超5*3090 |
|
8 |
RTX3090 |
5块 |
52480 |
178 |
1425 |
936 |
120 |
|
|
29 |
A5000 |
6块 |
49152 |
166 |
1302 |
768 |
144 |
全能高速 |
|
9 |
A6000 |
4块 |
43008 |
160 |
1248 |
768 |
192 |
全能高速 |
|
10 |
RTX3080 |
5块 |
43520 |
149 |
1190 |
760 |
50 |
超9*2080ti |
|
11 |
RTX3090 |
4块 |
41984 |
142 |
1140 |
936 |
96 |
|
|
12 |
RTX3070 |
7块 |
41216 |
142 |
1141 |
448 |
56 |
|
|
13 |
A5000 |
5块 |
40960 |
139 |
1085 |
768 |
120 |
全能高速 |
|
14 |
RTX2080Ti |
9块 |
39168 |
121 |
990 |
616 |
99 |
|
|
15 |
RTX3070 |
6块 |
35328 |
122 |
978 |
448 |
48 |
超7块Titan RTX |
|
16 |
RTX3080 |
4块 |
34816 |
119 |
952 |
760 |
40 |
超8*2080ti |
|
17 |
Titan RTX |
7块 |
32256 |
114 |
910 |
672 |
168 |
|
|
18 |
A5000 |
4块 |
32768 |
111 |
868 |
768 |
96 |
全能高速 |
|
19 |
RTX2080Ti |
8块 |
34816 |
108 |
880 |
616 |
88 |
|
|
20 |
RTX3090 |
3块 |
41984 |
107 |
855 |
936 |
72 |
|
|
21 |
RTX3070 |
5块 |
29440 |
102 |
815 |
448 |
40 |
|
|
22 |
RTX3080 |
3块 |
34816 |
89 |
714 |
760 |
40 |
超4*titanRTX |
|
23 |
A5000 |
3块 |
24576 |
84 |
651 |
768 |
72 |
全能高速 |
|
24 |
RTX3070 |
4块 |
23552 |
81 |
652 |
448 |
32 |
|
|
25 |
A6000 |
2块 |
21504 |
80 |
624 |
768 |
96 |
全能高速 |
|
26 |
RTX3090 |
2块 |
20992 |
71 |
570 |
936 |
48 |
|
|
27 |
Titan RTX |
4块 |
18432 |
65 |
520 |
672 |
96 |
|
|
28 |
RTX3070 |
3块 |
23552 |
61 |
489 |
448 |
24 |
|
|
29 |
RTX3080 |
2块 |
17408 |
60 |
476 |
760 |
20 |
多用途 |
|
30 |
A5000 |
2块 |
16384 |
56 |
432 |
768 |
48 |
全能高速 |
|
31 |
RTX2080Ti |
4块 |
17408 |
54 |
440 |
616 |
44 |
|
|
32 |
RTX2080s |
4 |
12288 |
44 |
252 |
496 |
32 |
|
|
33 |
RTX3070 |
2块 |
11776 |
41 |
326 |
448 |
16 |
超3090 |
|
34 |
A6000 |
1块 |
10752 |
40 |
312 |
768 |
48 |
全能高速 |
|
35 |
RTX3090 |
1块 |
10496 |
36 |
285 |
936 |
24 |
全能高速 |
|
36 |
Titan RTX |
2块 |
9216 |
32 |
260 |
672 |
48 |
|
|
37 |
RTX3080 |
1块 |
8704 |
30 |
238 |
760 |
10 |
科研型 |
|
38 |
A5000 |
1块 |
8192 |
28 |
217 |
768 |
24 |
全能高速 |
|
39 |
RTX2080Ti |
2块 |
8704 |
28 |
220 |
616 |
22 |
|
|
40 |
RTX2080s |
2块 |
3072 |
22 |
126 |
496 |
16 |
|
|
41 |
RTX3070 |
1块 |
5888 |
20 |
163 |
448 |
8 |
科研型 |
|
42 |
Titan RTX |
1块 |
4608 |
16 |
130 |
672 |
24 |
|
|
43 |
TITAN V |
1 |
5120 |
14.90 |
110 |
653 |
12 |
|
|
44 |
RTX2080Ti |
1块 |
4352 |
13 |
110 |
616 |
11 |
|
#p#page_title#e#
目录
1 提升深度学习算力的最新硬件方案
2 深度学习选择GPU-性能指标最新排序
3 UltraLAB深度学习工作站新机型介绍
4 UltraLAB 深度学习工作站基准配置方案2021v2
4.1 GA300i深度学习工作站配置推荐(2块GPU方案,超值型)
4.2 GT410P深度学习工作站配置推荐(最大5块GPU方案,高性能型)
4.3 GX650M深度学习工作站配置推荐(最大6块GPU方案,完美极致型)
三.UltraLAB深度学习工作站新机型介绍
西安坤隆计算机科技有限公司2021年6月新上市两款机型GA300i、GX650M,其特点支持超频、支持PCIe4.0接口,其技术规格如下:
机型1 UltraLAB GA300i产品介绍
配置规格:
CPU 支持intel第11代酷睿处理器(8核@5Ghz-全核超频)
内存 最大128GB(双通道)
GPU卡 最大2块RTX30系列
PCIe接口 双PCIe 4.0 x8或单PCIe 4.0 x16
噪音等级 静音级
产品说明:
双槽/三槽GPU卡通吃
比常规CPU频率的机器,在数据预处理方面提升显著
售前:提供远程测试
机型2 UltraLAB GX650M产品介绍

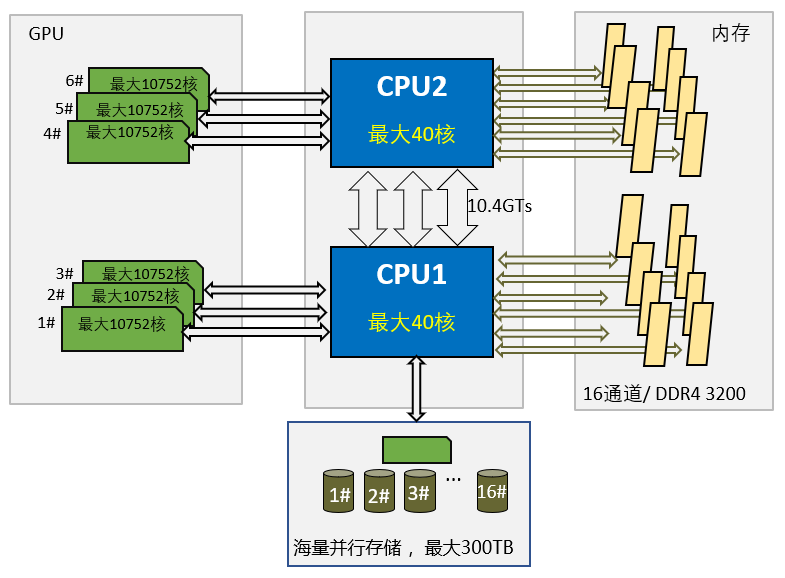
配置规格:
CPU: 2颗Xeon第3代可扩展处理器(最大80核)
内存:最大4TB(16通道)
GPU卡: 最大6块RTX30系列
PCIe接口:6个PCIe 4.0 x16(6个全速),1个PCIe 4.0 x8
并行存储:16个3.5寸硬盘位
噪音等级:静音级
产品说明:
双槽/三槽GPU卡通吃
PCIe4.0比PCIe3.0架构拥有更快的数据带宽,整体性能提升显著(可远程测试)
内存带宽提升(16通道)
最大300TB并行存储
GX650M在深度学习关键配置选项
|
No |
关键硬件 |
解决方案 |
|
1 |
硬盘读取速度 |
选项1 2TB M2.SSD PCIe 4.0接口,读写带宽7GB/s、5GB*/s 选项2 3.84TB/7.68TB PCIe-SSD卡,PCIe 4.0 4x, |
|
2 |
PCIe传输速度 |
6个 PCIe 4.0 x16(全速) |
|
3 |
CPU频率 |
2颗Xeon 金牌6328H(共计32核@3.7GHz,睿频4.3GHz,基频2.8GHz) 2颗Xeon 铂金8354H(共计36核@4.0GHz,睿频4.2GHz,基频3.1GHz) 2颗Xeon 铂金8360H(共计48核@3.8GHz,睿频4.2GHz,基频3.0GHz) 2颗Xeon 铂金8380H(共计56核@3.8GHz,睿频4.3GHz,基频2.9GHz) |
|
4 |
内存 |
最大16通道,DDR4 3200 RECC 192GB(12*16GB) 512GB(16*32GB) 768GB(12*64GB) 1TB(16*64GB) |
|
5 |
GPU卡 |
可选型号: RTX3080 10GB/RTX3090 24GB A5000 24GB/A6000 48Gb 数量 最大6块 |
售前:提供远程测试
#p#page_title#e#
目录
1 提升深度学习算力的最新硬件方案
2 深度学习选择GPU-性能指标最新排序
3 UltraLAB深度学习工作站新机型介绍
4 UltraLAB 深度学习工作站基准配置方案2021v2
4.1 GA300i工作站配置推荐(2块GPU方案,超值型)
4.2 GT410P深度学习工作站配置推荐(最大5块GPU方案,高性能型)
4.3 GX650M深度学习工作站配置推荐(最大6块GPU方案,完美极致型)
四 UltraLAB 深度学习工作站配置方案2021v2
2.1 图灵计算工作站(GA300i)配置推荐(超值型)
技术特点:
CPU高频、最多2块GPU卡(PCIe 4.0 x8接口),超高性价比
GA300i配置推荐:
|
No |
产品型号 |
主要配置 |
显存 |
CUDA处理器FP32性能指标 |
张量处理器FP16性能指标 |
理想算法 |
价格 |
|
1.1 |
GA300i 14832-SAX |
intel第11代高频处理器 ( 8核4.8Ghz)/32GB DDR4/ RTX3080 10GB/960GB SSD /4TB SATA/微塔式(2000w) /23"图显 |
10GB |
30Tops |
238Tops |
CNN |
¥38,500 |
|
1.2 |
GA300i 14864-SAT |
intel第11代高频处理器 (8核4.8Ghz)/64GB DDR4/ RTX3090 24GB /1.9TB SSD /6TB SATA/微塔式(2000w) /23"图显 |
24GB |
36Tops |
285Tops |
CNN+ RNN 多用途 |
¥54,000 |
|
1.3 |
GA300i 14832-SA2X |
intel第11代高频处理器(8核@4.8Ghz)/32GB DDR4/2*RTX3070 8GB/1.9TB SSD /6TB SATA/微塔式(2000w)/23"图显 |
16GB |
41Tops |
326Tops |
CNN高性价比 |
¥49,990 |
|
1.4 |
GA300i 15064-SB2X |
intel第11代高频处理器(8核@5.0Ghz)/64GB DDR4/2*RTX3080 10GB/1.9TB SSD/6TB SATA/微塔式(2000w)/23"图显 |
20GB |
60Tops |
476Tops |
CNN 超4*2080ti |
¥68,000 |
|
1.5 |
GA300i 15096-SC2T |
intel第11代处理器(8核5.0Ghz) /96GB DDR4 /2*RTX3090 24GB /3.84TB SSD /8TB SATA/微塔式(2000w)/23"图显 |
48GB |
71Tops |
570Tops |
CNN+ RNN 超4块Titan RTX |
¥83,000 |
|
1.6 |
GA300i 150128-SC2D |
intel第11代处理器(8核5.0Ghz) /128GB DDR4 /2*A5000 24GB/ 3.84TB SSD /8TB SATA/微塔式(2000w)/23"图显 |
48GB |
56Tops |
520Tops |
CNN+ RNN 超4块2080TI |
¥94,500 |
|
1.7 |
GA300i 150128-SC2E |
intel第11代处理器( 8核5.0Ghz) /128GB DDR4 /2*A6000 48GB/ 3.84TB SSD /8TB SATA/微塔式(2000w)/23"图显 |
96GB |
80Tops |
624Tops |
CNN+ RNN 超4块Titan RTX |
¥145,000 |
#p#page_title#e#
目录
1 提升深度学习算力的最新硬件方案
2 深度学习选择GPU-性能指标最新排序
3 UltraLAB深度学习工作站新机型介绍
4 UltraLAB 深度学习工作站基准配置方案2021v2
4.1 GA300i深度学习工作站配置推荐(2块GPU方案,超值型)
4.2 GT410P工作站配置推荐(最大5块GPU方案,高性能型)
4.3 GX650M深度学习工作站配置推荐(最大6块GPU方案,完美极致型)
2.2 图灵超算工作站(GT410P)配置推荐(高性能型)
技术特点:
超高CPU频率,最多5块GPU卡(双槽卡、三槽卡通吃),支持并行存储,
GT410P配置推荐:
|
No |
产品型号 |
主要配置 |
显存 |
CUDA处理器FP32性能指标 |
张量处理器FP16性能指标 |
理想算法 |
价格 |
|
2.1 |
GT410P 14664-MB4X |
intel第10代至尊处理器(10核4.6Ghz)/64GB DDR4/4*RTX3070 /2TB M2.SSD+6TB SATA/双塔式(双2000w) /27"-4K图显 |
32GB |
81Tops |
652Tops |
CNN |
¥94,500 |
|
2.2 |
GT410P 14596-MB5X |
intel第10代至尊处理器(12核4.5Ghz )/96GB DDR4/5*RTX3070 /2TB M2.SSD+8TB SATA/双塔式(双2000w) /27"-4K图显 |
40GB |
102Tops |
815Tops |
CNN |
¥112,000 |
|
2.3 |
GT410P 145128-MB3T |
intel第10代至尊处理器(12核4.5Ghz)/128GB DDR4/3*RTX3090/ 960GB SSD/2TB M2.SSD/10TB SATA /双塔式(双2000w)/27"-4K图显 |
72GB |
107Tops |
855Tops |
高性能多用途 |
¥129,990 |
|
2.4 |
GT410P 145128-MB4X |
intel第10代至尊处理器(12核4.5Ghz)/128GB DDR4/4*RTX3080/ 960GB SSD/2TB M2.SSD/10TB SATA/双塔式(双2000w) /27"-4K图显 |
40GB |
119Tops |
952Tops |
性能超8块2080ti |
¥129,990 |
|
2.5 |
GT410P 144192-MB4T |
intel第10代至尊处理器( 14核4.4Ghz)/192GB DDR4/4*RTX3090/ 960GB SSD/2TB M2.SSD/12TB SATA/双塔式(双2000w )/27"-4K图显 |
96GB |
142Tops |
1.14PTos |
性能超7块TitanRTX |
¥159,990 |
|
2.6 |
GT410P 144128-MB5X |
intel第10代至尊处理器(14核4.4Ghz)/128GB DDR4/5*RTX3080/ 960GB SSD/2TB M2.SSD/10TB SATA /双塔式(双2000w)/27"-4K图显 |
50GB |
149Tops |
1.19PTos |
CNN |
¥155,000 |
|
2.7 |
GT410P 144256-MB5T |
intel第10代至尊处理器(14核4.4Ghz)/256GB DDR4/5*RTX3090/ 1.9TB SSD/2TB M2.SSD/12TB SATA /双塔式(双2000w)/27"-4K图显 |
120GB |
178Tops |
1.43PTos |
高性价比多用途 |
¥189,000 |
|
2.8 |
GT410P 144192-MB5D |
intel第10代至尊处理器(14核4.4Ghz)/192GB DDR4/5*A5000/ 1.9TB SSD/2TB M2.SSD/12TB SATA /双塔式(双2000w)/27"-4K图显 |
120GB |
139Tops |
1.08PTos |
超高性价比海量计算 |
¥210,000 |
|
2.9 |
GT410P 144256-MB5E |
intel第10代至尊处理器(14核4.4Ghz)/256GB DDR4/5*A6000/ 1.9TB SSD/2TB M2.SSD/12TB SATA /双塔式(双2000w)/27"-4K图显 |
240GB |
200Tops |
1.56PTos |
极致性能海量计算 |
¥335,000 |
#p#page_title#e#
目录
1 提升深度学习算力的最新硬件方案
2 深度学习选择GPU-性能指标最新排序
3 UltraLAB深度学习工作站新机型介绍
4 UltraLAB 深度学习工作站基准配置方案2021v2
4.1 GA300i深度学习工作站配置推荐(2块GPU方案,超值型)
4.2 GT410P深度学习工作站配置推荐(最大5块GPU方案,高性能型)
4.3 GX650M深度学习工作站配置推荐(最大6块GPU方案,完美极致型)
2.3 图灵超算工作站(GX650M)配置推荐(极致型)
技术特点:
高主频,最多6块GPU卡(全部PCIe 4.0 x16,双槽卡、三槽卡通吃),PCIe4.0 接口SSD卡,支持最大16个判为海量并行存储,
每个环节都达到最佳,完美、强大的深度学习配置架构,还是静音级
GX650M配置推荐
|
No |
产品 型号 |
主要配置 |
显存 |
CUDA处理器FP32性能指标 |
张量处理器FP16性能指标 |
理想算法 |
价格 |
|
4.1 |
GX630M 236192- 42T5X |
2*Xeon金6346 (32核3.6GHz)/ 192GB DDR4/ 5*RTX3070 / 3.84TB SSD/ 42TB并行存储/ 双塔式(双2000w)/ 27"-4K图显 |
40GB |
102Tops |
815Tops |
CNN |
¥189,990 |
|
4.2 |
GX650M 236256- 56T6X |
2*Xeon金6346 (32核3.6GHz)/ 256GB DDR4/ 6*RTX3070 / 3.84TB SSD/ 56TB并行存储/ 双塔式(双2000w)/ 27"-4K图显 |
48GB |
122Tops |
978Tops |
CNN |
¥205,000 |
|
4.3 |
GX650M 236256- 42T5X |
2*Xeon金6346 (32核3.6GHz)/ 256GB DDR4/ 5*RTX3080/ 1.92TB SSD/ 2TB M2 SSD/ 42TB并行存储/ 双塔式(双2000w)/ 27"-4K图显 |
50GB |
149Tops |
1.19PTos |
计算机视觉完美型 |
¥226,000 |
|
4.4 |
GX650M 236256- 42T4D |
2*Xeon金6346 (32核3.6GHz)/ 256GB DDR4/ 4*A5000/ 1.92TB SSD/ 2TB M2 SSD/ 42TB并行存储/ 双塔式(双2000w )/ 27"-4K图显 |
96GB |
111Tops |
880Tops |
CNN+RNN全能型 |
¥249,000 |
|
4.5 |
GX650M 236256- 56T6X |
2*Xeon金6354 (36核3.6GHz)/ 256GB DDR4/ 6*RTX3080/ 1.92TB SSD/ 2TB M2 SSD/ 56TB并行存储/ 双塔式(双2000w)/ 27"-4K图显 |
60GB |
179Tops |
1.43PTos |
CNN最快 |
¥259,000 |
|
4.6 |
GX650M 243384- 80T4T |
2*Xeon金6354 (32核3.6GHz)/ 384GB DDR4/ 4*RTX3090/ 1.92TB SSD/ 2TB M2 SSD/ 80TB并行存储/ 双塔式(双2000w)/ 27"-4K图显 |
96GB |
142Tops |
1.14PTfops |
全能+完美 |
¥268,000 |
|
4.7 |
GX650M 234384- 90T5T |
2*Xeon金6348 (56核3.4GHz)/ 384GB DDR4/ 5*RTX3090/ 1.92TB SSD/ 2TB M2 SSD/ 90TB并行存储/ 双塔(双2000w)/ 27"-4K图显 |
120GB |
178Tops |
1.43PTos |
全能+极致 |
¥299,500 |
|
4.8 |
GX650M 236512- 120T6T |
2*Xeon金6354 (36核3.6GHz)/ 512GB DDR4/ 6*RTX3090 / 3.84TB SSD/ 2TB M2.SSD/ 120TB并行存储/ 双塔式(双2000w)/ 32"-4K图显 |
144GB |
213Tops |
1.71PTos |
近16块Titan V最快最完美 |
¥395,000 |
|
4.9 |
GX650M 236768- 150T6D |
2*Xeon金6354 (36核3.6GHz)/ 768GB DDR4/ 6*A5000/ 1.92TB SSD/ 2TB M2.SSD/ 150TB并行存储/ 双塔式(双2000w)/ 32"-4K图显 |
144GB |
166Tops |
1.33PTos |
最快最完美,性能超DGX-2 |
¥399,990 |
|
4.10 |
GX650M 236384- 150T5E |
2*Xeon金6354 (36核3.6GHz)/ 384GB DDR4/ 5*A6000/ 1.92TB SSD/ 2TB M2.SSD/ 150TB并行存储/ 双塔式(双2000w)/ 32"-4K图显 |
240GB |
200Tops |
1.56PTos |
CNN+ RNN+ 推理 |
¥480,000 |
|
4.11 |
GX650M 2331T- 240T6E |
2*Xeon铂金8358 (64核3.3GHz)/ 1TB DDR4/ 6*A6000/ 3.84TB SSD/ 2TB M2.SSD/ 240TB并行存储/ 双塔式(双2000w)/ 32"-4K图显 |
288GB |
240Tops |
1.8PTos |
最强最完美,性能超DGX-2 |
¥630,000 |
最新xeon三代+PCIe 4.0架构-深度学习训练、AI智能、神经元计算基准配置推荐2021v2
最新AMD锐龙Pro+PCIe 4.0架构-深度学习训练、AI智能、神经元计算基准配置推荐2021v3
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800



