






地表最强深度学习训练平台~UltraLAB GPU硬件选型
目录
1 深度学习训练平台与理想计算架构
2 深度神经网络计算特点与硬件配置分析
3 UltraLAB GXM图灵工作站与配置推荐
2018年8月最新深度学习基准配置报价下载(直接点击,GPU更新为RTX2080/2080Ti)
(一)深度学习训练平台现状与完美计算架构
深度神经网络(DNN)计算数据模型繁多,结构复杂,主流模型含几十个隐含层,每层都在上千上万级的神经元,整个网络更多,其计算量巨大,
市场上用于深度学习的训练计算机大致情况,
(1)服务器/工作站(支持2、4、8块GPU架构):普遍存在噪音大,无法放置于办公环境,必须放到专门的机房,维护成本高,另外数据存储带宽、延迟、容量也不尽如意
(2)分布式集群架构:性能强大,但是开发成本太高,是大多数科研单位无法承受
那么问题来了,市场上是否有一个理想产品,弥补上述缺陷,让更多单位都能用的起~人工智能AI超级异构计算机

UltraLAB GXM图灵计算工作站是西安坤隆计算机公司2017年上半年推出的、目前市场上一款集GPU超算、海量存储于一体、基于办公静音环境、应用于深度学习(机器学习、人工智能)的AI超级计算机系统。
和市面上深度学习计算机系统相比,显著优势:
- 完全处于办公环境(静音级)、不在被噪音所困扰
- 配备基于PCIe总线的海量高速并行存储(最大容量180TB),延迟低,支持最大15个并行读,硬盘io性能大幅提升,性能和管理远超传统的DAS/NAS存储系统
- 配备超级强大的计算能力,最大10个GPU卡,3.82万计算核,单精度浮点120Tflops
- 不需要专门的机房,不占过多空间,维护成本极低
- 不需要作业调度系统,管理难度大幅降低
(二)深度神经网络计算特点与硬件配置分析
市场上大部分GPU计算机(服务器/工作站),重点都放在GPU卡数量上,似乎只要配上足够GPU卡,就可以了,实际情况是,机器硬件配置还需要整体均衡,只有这样这台机器性能才能更好的发挥
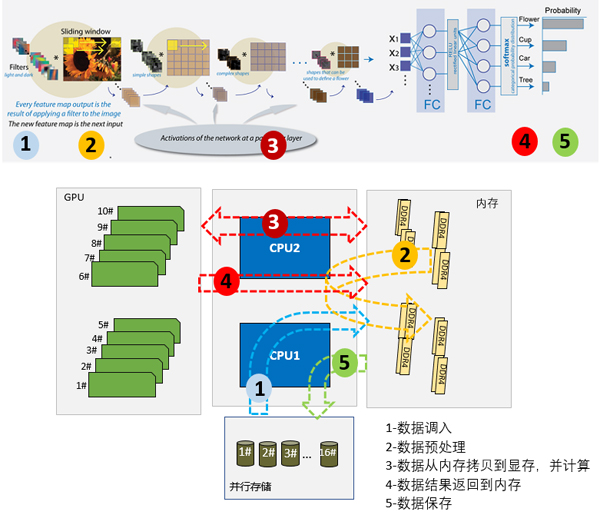
上述图示,深度神经网络计算大致流程,下面通过深度神经网络计算环节,分析核心硬件配置理想要求
1.数据存储要求
做深度学习首先需要一个好的存储系统,将历史资料保存起来
主要任务:历史数据存储,如:文字、图像、声音、视频、数据库等。。。
性能要求:
a.数据容量:提供足够高的存储能力,
b.读写带宽:多硬盘并行读写架构提高数据读写带宽
c.接口:高带宽,同时延迟低
传统解决方式:专门的存储服务器,借助万兆端口访问
缺点:带宽不高,对深度学习的数据读取过程时间长(延迟大,两台机器之间数据交换),成本高
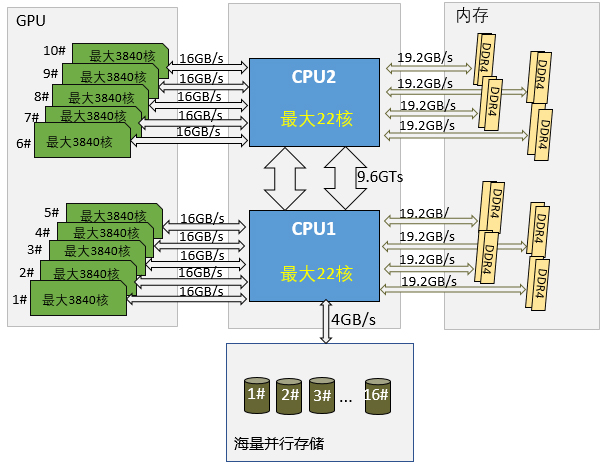
UltraLAB解决方案:将并行存储直接通过PCIe接口,提供最大16个硬盘的并行读取,数据量大并行读取要求高,无论是总线还是硬盘并行带宽,都得到加大提升,满足海量数据密集io请求和计算需要
2.CPU要求
主要任务:
(1)数据从存储系统调入到内存的解压计算
(2)GPU计算前的数据预处理
(3)运行在代码中写入并读取变量执行指令,如函数调用启动在GPU上函数调用,创建小批量数据启动到GPU的数据传输
(4)GPU多卡并行计算前,每个核负责一块卡的所需要的数据并行切分处理和控制
(5)求解后数据保存前的压缩计算
上述每一类操作基本都是单核计算模式, 如果要加速这些过程,唯有提升CPU频率
传统解决方式:CPU规格很随意,核数和频率没有任何要求
UltraLAB合理推荐:
a.CPU频率:越高越好
b.CPU三级缓存:越大越好
c.CPU核数:比GPU卡数量大(原则:1核对应1卡,核数要有至少2个冗余)
3.GPU要求
主要任务:承担深度学习的数据建模计算、运行复杂算法
传统架构:提供1~8块GPU
UltraLAB合理推荐:
a.数据带宽:PCIe8x 3.0以上
b.数据容量:显存大小也很关键
c.计算匹配:CPU核-GPU卡 1对1
d.GPU卡加速:多卡提升并行处理效率
4 内存要求
主要任务:存放预处理的数据,待GPU读取处理,中间结果存放
UltraLAB合理推荐:
a.数据带宽最大化:单Xeon E5v4 4通道内存,双Xeon E5v4 8通道内存,内存带宽最大化
b.内存容量合理化:大于GPU总显存
#p#page_title#e#
(三)UltraLAB GXM图灵计算工作站介绍与配置推荐
针对上述深度学习应用计算特点,UltraLAB图灵工作站具有深度学习最合理硬件配置架构,保证整个机器是一台理想化异构超算系统,完美强大高效还静音,目前提供两种机型:GX480M和GX610M

3.1 图灵计算工作站技术规格
|
机型 |
硬件配置规格 |
|||
|
CPU |
GPU |
内存 |
存储 |
|
|
GX480M |
单CPU架构,6核4.5GHz,8核4.3GHz,10核43GHz |
最大6块GPU |
最大256GB |
并行存储, 最大180TB |
|
GX610M |
双Xeon架构, 2*Xeon E5 2637v4(共计8核3.5GHz) 2*Xeon E5 2643v4(共计12核3.4GHz) 2*Xeon E5 2667v4(共计16核3.2GHz) |
最大10块GPU |
最大1TB |
并行存储, 最大180TB |
技术规格一览表
(1)GX480M技术规格一览表
|
NO |
主要项 |
技术规格 |
|
1 |
CPU |
1颗intel 至尊处理器 推荐型号:6850K OC(6核4.5GHz) 6900K OC(8核4.3GHz) 6950X OC(10核4.3GHz) Xeon E5 2687Wv4(12核3.0GHz) |
|
2 |
芯片组 |
intel X99+PCH |
|
3 |
内存 |
插槽:8个, 规格:DDR4 2400 Reg ECC 最大容量:256GB(8根32GB) |
|
4 |
GPU卡 |
数量:最大7个 接口:PCIE 8x 3.0 GPU种类:Nvidia Geforce、Quadro、Tesla Intel Xeon Phi,AMD Firepro 备注:散热系统必须是主动式 |
|
5 |
系统盘 |
数量: 2块 单盘容量:512GB/1TB/2TB/4TB SSD SATA-6Gbps接口, 支持RAID1 |
|
|
数据盘 |
数量:16块, 单盘容量:4TB/6TB/8TB/10TB/12TB SATA 企业级, 最大容量180TB(RAID5),PCIe 4x 2.0接口 |
|
6 |
光驱 |
DVD刻录 |
|
7 |
平台 |
型号UltraLAB S2AGDT01PCS 电源 1600w,数量1个(四块GPU卡)或2个(5个以上) 机箱:双塔式 机箱尺寸:深度658mm,宽度478mm,高度674mm 输出口: 2个千兆以太端口(可选万兆), 4个USB 3.0口,2个USB2.0,1个VGA口 硬盘位:16个3.5”热插拔,最大容量180TB PCI扩展槽:7个PCIe 16x |
|
8 |
键盘鼠标 |
键盘:104键、有线、USB口, 鼠标:1000dpi精度、光电、有线、USB口 |
|
9 |
显示器 |
23”图显(高清,可升降转向,数量2台) |
|
10 |
整机优化 |
*2.1 自动超频加速优化; *2.2 高性能低延迟优化; |
|
11 |
操作系统 |
支持Window 7/8/10, Windows 2008/2012/2016 支持Ubuntu 全系列 |
|
12 |
支持深度学习框架 |
Nvidia GPU驱动程序,CUDA , Nvidia Digits, Nvidia cuDNN Caffe,Torch ,TensorFlow,CNTK,Theano, Chainer,DL4J,MXNet |
(2)GX610M技术规格一览表
|
NO |
主要项 |
技术规格 |
|
1 |
CPU |
2颗Xeon E5 2600v4 推荐型号:Xeon E5 2637v4(4核3.5GHz) Xeon E5 2643v4 (6核3.4GHz) Xeon E5 2667v4(8核3.2GHz) Xeon E5 2687Wv4(12核3.0GHz) |
|
2 |
芯片组 |
intel C612+PCH |
|
3 |
内存 |
插槽:16个, 规格:DDR4 2400 Reg ECC 最大容量:1TB(16根64GB) |
|
4 |
GPU卡 |
数量:最大10个 接口:PCIE 8x 3.0 GPU种类:Nvidia Geforce、Quadro、Tesla Intel Xeon Phi,AMD Firepro 备注:散热系统必须是主动式 |
|
5 |
系统盘 |
数量: 2块 单盘容量:512GB/1TB/2TB/4TB SSD SATA-6Gbps接口 支持RAID1 |
|
|
数据盘 |
数量:16块, 单盘容量4TB/6TB/8TB/10TB/12TB SATA 企业级, 最大容量180TB(RAID5),PCIe 4x 2.0接口 |
|
6 |
光驱 |
DVD刻录 |
|
7 |
平台 |
型号UltraLAB S2AGDT01PCS 电源 1600w,数量1个(四块GPU卡) 或2个(5个以上) 机箱:双塔式 机箱尺寸:深度658mm,宽度478mm,高度674mm 输出口: 2个千兆以太端口(可选万兆) 4个USB 3.0口,2个USB2.0,1个VGA口 硬盘位:16个3.5”热插拔,最大容量180TB PCI扩展槽:10个PCIe 8x 3.0, 1个PCIe 4x 2.0 |
|
8 |
键盘鼠标 |
键盘:104键、有线、USB口, 鼠标:1000dpi精度、光电、有线、USB口 |
|
9 |
显示器 |
23”图显(高清,可升降转向,数量2台) |
|
10 |
整机优化 |
*2.1 自动超频加速优化; *2.2 高性能低延迟优化; |
|
11 |
操作系统 |
支持Window 7/8/10, Windows 2008/2012/2016 支持Ubuntu 全系列 |
|
12 |
支持深度学习框架 |
Nvidia GPU驱动程序,CUDA ,Nvidia Digits, Nvidia cuDNN,Caffe,Torch ,TensorFlow, CNTK,Theano,Chainer,DL4J,MXNet |
3.2 产品特点
(1)集GPU超算、并行存储于一体的超级训练系统
基于办公环境,静音级
支持最大10块GPU超算,单精度浮点最大到120Tflops
配备高速并行存储(16个盘位),最大180TB容量
支持双Xeon E5v4高频处理器,加速密集预处理、高强度数据压缩等计算环节
拥有CPU+GPU完美的深度学习架构
(2)预装完整开发工具的硬件系统,帮助快速启动深度学习研究项目
基于GPU工作站系统,预装深度学习所需的软件:Nvidia 驱动程序,CUDA工具包,cuDNN,开源工具TensorFlow,Cafe,Torch,NVIDIA DIGITS等
#p#page_title#e#
3.3深度学习工作站硬件配置参考
(1)GX480M机型配置参考(超值型)
该机型特点:支持最大到6块GPU卡,CPU的频率达到极致,每个环节保证达到最理想性能,整体配置均衡无死角,满足深度学习训练硬件配置要求
|
NO |
CPU |
内存 |
GPU/总显存 |
单精度 |
系统盘 |
并行存储 |
平台 |
售价 |
|
1 |
6850K OC (6核4.5GHz) |
32GB |
1块GTX1080 8GB |
8Tflops |
512GB SSD |
4TB |
双塔单电 |
46500 |
|
2 |
6850K OC (6核4.5GHz) |
32GB |
2块GTX1080 16GB |
16Tflops |
512GB SSD |
2*4TB |
双塔单电 |
55000 |
|
3 |
6850K OC (6核4.5GHz) |
64GB |
3块GTX1080 24GB |
24Tflops |
512GB SSD |
3*4TB |
双塔单电 |
67500 |
|
4 |
6900K OC (8核4.3GHz) |
64GB |
4块GTX1080 32GB |
32Tflops |
1TB SSD |
28TB |
双塔单电 |
98000 |
|
5 |
6900K OC (8核4.3GHz) |
96GB |
6块GTX1080Ti 66GB |
68Tflops |
1TB SSD |
36TB |
双塔双电 |
149990 |
备注:含双23”高清图显
(2)GX610M机型配置参考(高性能型)
该机型特点:支持最大到10块GPU卡,CPU的频率和核数达到最大均衡,每个环节保证达到最高性能,整体配置均衡无死角,满足深度学习训练对配置的要求
|
NO |
CPU |
内存 |
GPU/总显存 |
单精度浮点 |
系统盘 |
并行存储 |
平台 |
售价 |
|
1 |
2*Xeon E5v4 8核3.5GHz |
64GB |
4块GTX1080 32GB |
33Tflops |
512GB SSD |
28TB |
双塔单电 |
111000 |
|
2 |
2*Xeon E5v4 12核3.4GHz |
128GB |
6块GTX1080Ti 66GB |
68Tflops |
1TB SSD |
36TB |
双塔单电 |
182000 |
|
3 |
2*Xeon E5v4 12核3.4GHz |
192GB |
8块GTX1080Ti 88GB |
91Tflops |
1TB SSD |
44TB |
双塔双电 |
215000 |
|
4 |
2*Xeon E5v4 16核3.2GHz |
256GB |
9块GTX1080Ti 99GB |
102Tflops |
1TB SSD |
60TB |
双塔双电 |
248000 |
|
5 |
2*Xeon E5v4 16核3.2GHz |
512GB |
9块GTX1080Ti 99GB |
102Tflops |
1TB SSD |
120TB |
双塔双电 |
310000 |
|
6 |
2*Xeon E5v4 16核3.2GHz |
512GB |
9块 Quadro P5000 144GB |
79.74Tflops |
2TB SSD |
120TB |
双塔双电 |
415000 |
|
7 |
2*Xeon E5v4 24核3.0GHz |
512GB |
9块 Quadro P6000 216GB |
107.8Tflops |
2TB SSD |
150TB |
双塔双电 |
735000 |
备注:含双23”高清图显
关于GPU计算卡主要型号参考
|
No |
型号 |
显存 |
流处理器SP |
显存带宽 (GBs) |
浮点计算指标 TFLOPs (单精度) |
功耗 |
备注 |
|
1 |
Quadro P6000 |
24GB |
3840 |
432 |
11.98 |
250w |
显存和性能最大 |
|
2 |
Quadro P5000 |
16GB |
2560 |
288 |
8.86 |
180w |
显存更大 |
|
3 |
TITAN X |
12GB |
3584 |
480 |
10.97 |
250w |
|
|
4 |
GTX1080Ti |
11GB |
3584 |
484 |
11.33 |
250w |
性价比高 |
|
5 |
GTX1080 |
8GB |
2560 |
320 |
8.22 |
180w |
超值 |
|
6 |
GTX1070 |
8GB |
1920 |
256 |
5.78 |
150w |
超值 |
UltraLAB GXM在深度学习模型训练领域
除了热门的语音识别、图像识别、自然语言处理(机器翻译)外,更多应用
|
制造业 |
生产管理,事故预防,技术更新,不合格产品预判 |
|
医疗与护理 |
影像诊断,用药管理 |
|
零售,饮食,食品 |
自动记账,库存控制,店面防盗预防,内部检测,污染检测,可疑人物检测 |
|
安全监控 |
电梯监控,设备监控,店面监控 |
|
建筑与房地产 |
工程管理,事故预防,房地产信息查询,设施监控 |
|
农业与海洋 |
浇水附加肥料,除草和培育作物管理和病虫害防治,野生动物损害控制,水质监测管理,饲养和运输调整,航运 |
|
仓储与物流 |
库存管理,事故预防,转运和设备维护,异常监测 |
|
广告与营销 |
客户响应分析,客户行为分析 |
总结
UltraLAB GXM是一款静音级超级异构计算能力的深度学习训练计算机,比市面上的机器,更安静,性能更强大,适合科研、研究部门在安静的办公环境下运行。
此外,该机型用途极广,扩展能力强, 调整配置后,可为电磁仿真计算(CST)、量子化学/分子动力学计算(VASP、AMBER等)、超大屏拼接(8X9=72路视频拼接合成)、视频剪辑合成、指纹识别等应用,提供强悍的计算、图形生成能力
方案咨询
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
微信



