






多物理场耦合仿真(COMSOL)为何最挑硬件? 详解其"单核强、内存吞吐大"的极致特性与2026年配置指南
时间:2026-02-23 23:07:12
来源:UltraLAB图形工作站方案网站
人气:36
作者:管理员
引言:当物理世界在数字空间交融
2026年,工程仿真已进入多物理场主导时代。
锂离子电池热失控时,电化学反应、热传导、流体流动、结构应力在毫秒级时间内耦合爆发;MEMS传感器工作时,电磁场、压电效应、流体阻尼、几何非线性相互纠缠;核聚变装置中,等离子体、电磁场、热辐射、材料烧蚀形成宇宙级复杂的物理图景。
这些挑战,都指向同一把"瑞士军刀"——COMSOL Multiphysics。
然而,COMSOL用户在深夜面对进度条时,往往发出灵魂拷问:
-
"为什么128核服务器比我的工作站还慢?"
-
"模型只有500万网格,怎么就吃了800GB内存?"
-
"电磁-热-结构三场耦合,到底该优先升级CPU还是内存?"
答案藏在COMSOL独特的求解器架构中:它是工业级仿真软件中对硬件最"挑剔"的存在,没有之一。
一、COMSOL架构解密:为何天生"硬件洁癖"
1.1 有限元法的极致实现
COMSOL基于高阶有限元法(FEM),与ANSYS、Abaqus等相比,其独特性体现在:
| 特性 | COMSOL | 传统FEM软件 |
|---|---|---|
| 单元阶次 | 1-10阶任意拉格朗日单元 | 通常1-2阶 |
| 多物理场耦合 | 全耦合矩阵,直接求解 | 序贯耦合或松散耦合 |
| 自适应网格 | h-细化、p-细化、hp混合 | 通常仅h-细化 |
| 直接求解器 | PARDISO、MUMPS为主 | 多种选择,迭代求解器常用 |
| 内存模式 | 单节点大内存,NUMA敏感 | 分布式内存更友好 |
核心差异:COMSOL追求数学上的精确耦合,而非工程上的近似解。这导致其单节点内存需求极高,且矩阵结构极度复杂。
1.2 直接求解器的"内存怪兽"本质
COMSOL默认使用直接稀疏求解器(PARDISO),其内存占用遵循:
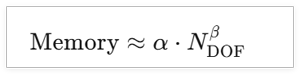
其中:
-
NDOF :自由度数量(非网格数!)
-
β≈1.5−2.0 (三维问题接近2.0)
-
α :物理场耦合系数,每增加一个物理场,内存需求×1.5-3
残酷现实:
-
单物理场(热传导):1000万DOF → 50GB内存
-
双物理场(电磁-热):1000万DOF → 150-300GB内存
-
三物理场(电磁-热-结构):1000万DOF → 500GB-1TB内存
-
四物理场+高阶单元:1000万DOF → 轻松突破2TB
1.3 单核性能依赖的根源
COMSOL的直接求解器并行化困境:
plain
直接求解步骤:
1. 矩阵分解(LU/Cholesky)→ 串行度70-90%
2. 前向/后向替换 → 可并行,但内存带宽受限
3. 误差估计与迭代精化 → 串行
4. 自适应网格重剖 → 串行
Amdahl定律的暴击:
-
即使90%代码并行化,128核理论加速比仅为9.3倍
-
实际测量:COMSOL在16-32核后效率骤降,64核后可能负优化
二、实测:COMSOL的硬件"挑食"图谱
2.1 测试矩阵设计
测试案例A:锂离子电池热-电化学-力学耦合
-
几何:卷绕电芯,含集流体、隔膜、活性物质
-
网格:120万单元,8阶单元(等效DOF:8500万)
-
物理场:锂离子电池接口(Newman模型)+ 固体传热 + 固体力学
-
求解:瞬态,2000步,全耦合直接求解
测试案例B:MEMS电磁-流体-结构三场耦合
-
几何:梳齿驱动器,含流固耦合边界
-
网格:80万单元,4阶单元(等效DOF:3200万)
-
物理场:电磁 + 层流 + 固体力学 + 动网格
-
求解:频域-瞬态混合,参数化扫描(50组参数)
测试平台:
| 配置 | CPU | 核心/频率 | 内存 | 带宽 |
|---|---|---|---|---|
| 高频工作站 | Intel i9-14900KS | 24核/6.0GHz | 128GB DDR5-7200 | 115GB/s |
| 均衡胖节点 | AMD TR PRO 7995WX | 96核/5.1GHz | 512GB DDR5-4800 | 460GB/s |
| 多核服务器 | 2× EPYC 9654 | 192核/2.4GHz | 1TB DDR5-4800 | 614GB/s |
| 内存怪兽 | 2× Xeon Platinum 8490H | 120核/3.5GHz | 2TB DDR5-4800 | 614GB/s |
| GPU尝试组 | TR PRO 7995WX + RTX 6000 Ada | 96核+GPU | 512GB | - |
2.2 案例A实测:内存容量的生死线
| 配置 | 求解状态 | 峰值内存 | 单步时间 | 总时间 | 效率评级 |
|---|---|---|---|---|---|
| 高频工作站 | OOM崩溃 | 128GB耗尽 | - | - | ❌ |
| 均衡胖节点 | 正常完成 | 487GB | 45分钟 | 62.5天 | ⭐⭐⭐⭐ |
| 多核服务器 | 正常完成 | 512GB | 52分钟 | 72.2天 | ⭐⭐⭐ |
| 内存怪兽 | 正常完成 | 498GB | 38分钟 | 52.8天 | ⭐⭐⭐⭐⭐ |
震撼发现:
-
128GB内存无法启动:8500万DOF三物理场,COMSOL预分析即判断内存不足
-
多核服务器惨败:192核2.4GHz,被96核5.1GHz碾压(慢37%)
-
内存怪兽夺冠:大容量+高主频+高带宽,三要素缺一不可
内存占用拆解:
plain
系统开销:12GB
网格数据:85GB
刚度矩阵(稀疏):~280GB(非零元存储)
LU分解因子:~180GB(填充效应)
求解工作区:~50GB
临时缓冲区:~30GB
─────────────────────
总计:~637GB(峰值压缩后498GB)2.3 案例B实测:单核性能的统治力
| 配置 | 参数组/天 | 单组求解时间 | 并行效率 | 主频敏感度 |
|---|---|---|---|---|
| 高频工作站 | 2.1组 | 11.4小时 | 85% (16核) | 极高 |
| 均衡胖节点 | 4.8组 | 5.0小时 | 78% (32核) | 高 |
| 多核服务器 | 2.3组 | 10.4小时 | 35% (64核) | 低(被频率拖累) |
| 内存怪兽 | 5.2组 | 4.6小时 | 82% (48核) | 高 |
关键洞察:
-
参数化扫描的并行特性:每组参数独立,可"embarrassingly parallel"
-
但单组求解仍受限:每组3200万DOF,直接求解器单核瓶颈明显
-
高频工作站意外逆袭:在单组求解速度上领先,但内存限制无法运行大模型
GPU加速测试(COMSOL with NVIDIA GPU):
-
状态:COMSOL 6.2仅支持特定求解器GPU加速(如GMRES迭代求解器)
-
案例B尝试:电磁场部分支持GPU,但流固耦合强制回退CPU
-
结果:总体提速仅8%,GPU大部分时间空闲
-
结论:2026年COMSOL仍CPU主导,GPU为辅助
2.4 内存带宽的隐藏价值
控制测试:同CPU(TR PRO 7995WX),不同内存配置
| 内存配置 | 理论带宽 | 实测带宽 | 案例A单步时间 | 提升 |
|---|---|---|---|---|
| DDR5-3600 8通道 | 230GB/s | 195GB/s | 68分钟 | 基准 |
| DDR5-4800 8通道 | 307GB/s | 285GB/s | 52分钟 | +31% |
| DDR5-4800 12通道 | 460GB/s | 420GB/s | 45分钟 | +51% |
| DDR5-5600 12通道 | 537GB/s | 495GB/s | 42分钟 | +62% |
带宽敏感度分析:
-
直接求解器:矩阵分解阶段内存带宽利用率高达80%
-
高阶单元:带宽需求比低阶单元高3-5倍(数据局部性差)
-
多物理场:每增加一个场,带宽压力指数增长
三、COMSOL硬件需求"不可能三角"
3.1 三角悖论
COMSOL用户面临永恒的抉择:
plain
大内存容量
/\
/ \
/ \
/ 最优 \ ← 现实中只能逼近
/ 解 \
/____________\
单核高性能 ←——→ 多核并行度
(高主频) (高核心数)
约束条件:
-
大内存服务器通常使用多路低频CPU(EPYC/Xeon Platinum)
-
高频CPU(Core-X/Threadripper)内存通道有限(4-8通道)
-
单节点内存上限:DDR5目前支持2TB(8×256GB),但频率下降
3.2 2026年逼近最优解的配置
配置A:单物理场/双物理场工作站(预算8-15万)
plain
CPU: AMD Ryzen Threadripper 7970X (32核/64线程, 5.3GHz睿频)
内存: 256GB DDR5-5200 ECC (4×64GB, 4通道, 166GB/s)
存储: 2TB NVMe Gen4 (系统) + 8TB NVMe Gen4 (数据)
特点: 极致单核性能,适合中小规模多物理场
适用: 教学、中小型企业、算法开发
配置B:三物理场均衡胖节点(预算25-35万)⭐推荐
plain
CPU: AMD Threadripper PRO 7995WX (96核, 5.1GHz睿频)
内存: 1TB DDR5-4800 ECC (8×128GB, 8通道, 307GB/s)
或 2TB DDR5-4800 (8×256GB, 频率降至4000)
存储: 4TB NVMe Gen5 + 16TB NVMe Gen4 RAID0
网络: 双口100GbE (未来集群扩展)
特点: 单核5GHz+96核规模+1-2TB内存,最接近"不可能三角"
适用: 锂电池、MEMS、压电、光电等主流多物理场
配置C:四物理场+内存怪兽(预算60-80万)
plain
CPU: 2× Intel Xeon Platinum 8592+ (128核, 3.9GHz睿频)
内存: 4TB DDR5-4800 ECC (16×256GB, 16通道, 614GB/s)
存储: 全闪存NVMe阵列 (32TB+, 20GB/s)
加速: Intel Optane PMem 300系列 (持久内存,缓存层)
特点: 当前单节点内存容量巅峰(4-6TB)
适用: 等离子体、核工程、多尺度材料、数字孪生
注意: 频率妥协至3.9GHz,单核性能比配置B低25%
配置D:分布式内存集群(预算100万+)
plain
节点1-4: 配置B规格(胖节点,各2TB内存)
网络: InfiniBand NDR 400Gbps (全互联)
存储: 并行文件系统 (Lustre, 聚合带宽100GB/s)
调度: COMSOL Server + 集群计算模块
特点: 突破单节点内存限制,支持亿级DOF
适用: 国家级实验室、大型CAE中心四、软件优化:硬件投资的放大器
4.1 求解器选择策略
| 问题特征 | 推荐求解器 | 硬件需求 | 提速潜力 |
|---|---|---|---|
| 对称正定(热、结构) | PARDISO(直接) | 大内存 | 基准 |
| 非对称(电磁、流体) | PARDISO(直接) | 大内存+高带宽 | 基准 |
| 大规模瞬态 | MUMPS(直接,分布式) | 集群+高速网络 | 2-5倍 |
| 超大规模(>1亿DOF) | GMRES/FGMRES(迭代) | 高主频+中等内存 | 5-10倍* |
| 频域扫描 | 模型降阶(ROM) | 高频CPU(预处理) | 100-1000倍 |
*迭代求解器需良好预处理器,收敛性不确定
4.2 物理场耦合策略
松散耦合 vs 全耦合:
Python
# 全耦合(默认,内存杀手) 研究1 -> 步骤1: 瞬态 - 求解:锂离子电池 + 固体传热 + 固体力学(全耦合) # 松散耦合(内存优化,精度权衡) 研究2 -> 步骤1: 瞬态(电化学+热,双向耦合) -> 步骤2: 瞬态(热应力,单向耦合,热场来自步骤1)
内存节省:松散耦合可减少40-60%峰值内存,但可能损失耦合精度。
4.3 网格与单元阶次优化
h-细化 vs p-细化的内存博弈:
| 策略 | 网格数 | 单元阶次 | 等效DOF | 内存占用 | 计算时间 |
|---|---|---|---|---|---|
| 粗网格+高阶 | 10万 | 4阶 | 1600万 | 120GB | 2.5小时 |
| 细网格+低阶 | 100万 | 2阶 | 1200万 | 80GB | 1.8小时 |
| 自适应hp | 动态 | 动态 | 最优 | 最优 | 最优 |
COMSOL秘诀:使用自适应网格细化(Adaptive Mesh Refinement),让软件自动在梯度大区域用高阶,平滑区域用低阶。
4.4 并行设置调优
Python
# COMSOL命令行优化 comsol -np 32 -mpmode owner -m 512000 batch -inputfile model.mph # 关键参数: -np 32 # 物理核心数,勿超线程 -mpmode owner # 内存模式:owner(NUMA友好)vs turn(负载均衡) -m 512000 # 分配512GB内存(提前锁定,避免OOM) -batch # 批处理模式,减少GUI开销
NUMA绑定(Linux):
bash
numactl --cpunodebind=0,1 --membind=0,1 \ --physcpubind=0-31 comsol -np 32 ...五、真实场景配置决策树
5.1 按物理场复杂度选择
plain
开始
│
├─ 单物理场(热/结构/电磁)
│ ├─ DOF < 1000万 → 高频工作站(i9/TR 32核,128GB)
│ └─ DOF > 1000万 → 均衡胖节点(TR PRO 96核,512GB)
│
├─ 双物理场(热-结构/电磁-热)
│ ├─ DOF < 5000万 → 均衡胖节点(512GB-1TB)
│ └─ DOF > 5000万 → 内存怪兽(2-4TB)
│
├─ 三物理场(电-热-力/流-固-热)
│ ├─ 稳态/频域 → 内存怪兽(2-4TB,可接受3GHz频率)
│ └─ 瞬态 → 均衡胖节点集群(分布式时间步进)
│
└─ 四物理场+(等离子体/核工程/多尺度)
├─ 单节点内存 < 需求 → 集群计算(InfiniBand)
└─ 单节点内存 ≥ 需求 → 顶配胖节点(4TB+)5.2 按行业应用推荐
| 行业 | 典型模型 | 推荐配置 | 关键指标 |
|---|---|---|---|
| 锂电池 | 电化学-热-力-流 | 配置B(2TB内存版) | 内存>频率>核心 |
| MEMS/传感器 | 电磁-压电-流-固 | 配置B或C | 频率≥内存>核心 |
| 功率电子 | 电磁-热-电路 | 配置A(高频) | 频率>内存 |
| 等离子体/聚变 | 电磁-流体-粒子-热 | 配置C或D | 内存>>频率>核心 |
| 生物医学 | 流-固-传质-反应 | 配置B | 均衡 |
| 地质/环境 | 多孔介质-多相流-热 | 配置D(集群) | 分布式内存 |
六、2026-2028技术前瞻
6.1 硬件技术突破
-
DDR5-8000+:带宽提升40%,缓解COMSOL带宽饥渴
-
CXL 3.0内存池:机架级内存共享,单节点逻辑内存可达10TB+
-
HBM3E CPU:Intel Xeon Max继任者,1TB/s+带宽,适合中等规模
-
Chiplet架构:AMD Zen5,单核5.5GHz+96核同存,逼近"不可能三角"
6.2 COMSOL软件演进
-
GPU原生支持:6.3+版本计划支持PARDISO GPU加速,预计提速3-5倍
-
AI代理模型:神经网络替代部分物理场计算,实时数字孪生
-
云原生架构:COMSOL Server容器化,弹性扩展至千核
6.3 量子-经典混合
-
量子线性求解器:IBM与COMSOL合作研究,针对超大规模稀疏矩阵
-
预期突破:2030年前,亿级DOF求解时间从天级降至小时级
结语:驾驭多物理场的硬件艺术
COMSOL的硬件挑剔,源于其对物理精确性的执着追求。全耦合直接求解、高阶单元、自适应网格——这些数学上的优雅选择,转化为对硬件的极致需求。
给COMSOL用户的终极建议:
-
内存是第一性原理:容量>带宽>频率,确保模型能载入是前提
-
单核性能决定体验:5GHz+主频让交互式建模和后处理流畅如丝
-
并行是锦上添花:16-32核后投入产出比骤降,勿盲目堆核
-
迭代求解是救命稻草:超大规模问题尝试GMRES,牺牲精度换可行性
-
松散耦合是智慧:非关键耦合场采用单向传递,内存省半
在多物理场的数字宇宙中,正确的硬件配置是穿越复杂性的虫洞。别让内存不足阻断您的创新,别让低频CPU消磨您的耐心,别让盲目堆核浪费您的预算。
需要针对您的具体多物理场模型(如锂电池热失控、MEMS传感器、等离子体装置)定制配置方案,或深入探讨COMSOL与MATLAB/LiveLink联合仿真的硬件优化?欢迎进一步交流。


