






优化高性能计算(HPC)的性能
如何能优化高性能计算(HPC)的性能?这个问题问的很好。从定性的层面上来说这个问题很容易回答,答案就是更快的处理器,更多容量的内存,表现更佳的网络和磁盘输入/输出子系统。但当你要在决定是否购买Linu集群时这样的回答就不够准确了。2007年6月网上技术交流会上(Webinar)所做的这个议题对于如何提高计算机性能做了详尽的论述。在此次议题中我们会使用更多的量化指标来做讲解。首先要论述的是对术语的定义来缩小此次议题的范围。
什么是高性能计算?
高性能计算简单来说就是在16台甚至更多的服务器上完成某些类型的技术工作负载。到底这个数量是需要8台,12台还是16台服务器这并不重要。在我们的定义下我们假设每一台服务器都在运行自己独立的操作系统,与其关联的输入/输出基础构造都是建立在COTS系统之上。简而言之,我们正在讨论的就是Linux高性能计算集群。
一个拥有20000台服务器的信息中心要进行分子动力学模拟无疑是毫无问题的,就好比一个小型工程公司在它的机房里运行计算流体动力学(CFD)模拟。解决工作负载的唯一限制来自于技术层面。接下来我们要讨论的问题是什么能直接加以应用。
量度(Metrics)
时至今日已经很少有人再讨论有关Linux高性能计算集群的纯性能问题。目前我们碰到的更多是这样的字眼:性能(Performance), 每瓦特性能(Performance/Watt), 每平方英尺性能(Performance/Square foot)和 性能价格比(Performance/dollar)等,对于上文提及的20000台服务器的动力分子簇来说,原因是显而易见的。运行这样的系统经常被服务器的能量消耗(瓦特)和体积(平方英尺)所局限。这两个要素都被计入总体拥有成本(TCO)之列。在总体拥有成本(TCO)方面取得更大的经济效益是大家非常关注的。
接着上面的论述,此次议题的范围我们限定在性能方面来帮助大家理解性能能耗,性能密度和总体拥有成本(TCO)在实践中的重要性。
性能的定义
在这里我们把性能定义为一种计算率。例如每天完成的工作负载,每秒钟浮点运算的速度(FLOPs)等等。接下来的讨论中我们要思考的是既定工作量的完成时间。这两者是直接关联的,速度=1/(时间/工作量)。因此性能是根据运行的工作量来进行测算的,通过计算其完成时间来转化成所需要的速度。
定量与定性
在上个章节中我们提到,此次议题是如何对Linux高性能计算集群的性能进行量化分析。为此我们接下来要介绍部分量化模型和方法技巧,它们能非常精确的对大家的业务决策进行指导,同时又非常简单实用。举例来说,这些业务决策涉及的方面包括:
购买---系统元件选购指南来获取最佳性能或者最经济的性能
配置---鉴别系统及应用软件中的瓶颈
计划---突出性能的关联性和局限性来制定中期商业计划
原型Linux集群(Prototypical Linux Cluster)
我们文中的Linux高性能计算集群模型包括四类主要的硬件组成部分。(1)执行技术工作负载的计算节点或者服务器 (2)一个用于集群管理,工作控制等方面的主节点 (3)互相连接的电缆和现在高度普及的千兆以太网(GBE) (4)一些全球存储系统,像由主节点输出的NFS文件一样简单易用。下面我们通过图示1来向大家进行详解。
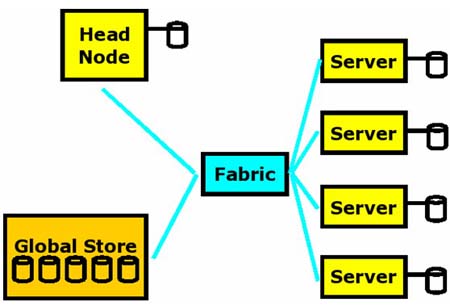
一个简单量化的运用模型
这样一个量化的运用模型非常直观。在一个集群上对既定的工作完成的时间大约等同于在独立的子系统上花费的时间:
e
(1)时间(Time)=节点时间(Tnode)+电缆时间(Tfabric)+存储时间(Tstorage)
Time = Tnode + Tfabric + Tstorag
这里所说的时间(Time)指的是执行工作量的完成时间,节点时间(Tnode)是指在计算节点上花费的完成时间,电缆时间(Tfabric)是指在互联网上各个节点进行互联的完成时间,而存储时间(Tstorage)则是指访问局域网或全球存储系统的完成时间。As in the webinar,有关电缆时间(Tfabric)和存储时间(Tstorage)的议题我们稍后会为大家陈述。我们先来关注节点时间(Tnode)这个关键词。计算节点的完成时间大约等同于在独立的子系统上花费的时间: #p#page_title#e#
(2)节点时间(Tnode)=内核时间(Tcore) +内存时间(Tmemory)
这里所说的内核时间(Tcore)指的是在微处理器计算节点上的完成时间。而内存时间(Tmemory)就是指访问主存储器的完成时间。这个模型对于单个的CPU计算节点来说是非常实用的,而且能很容易的扩展到通用双插槽(SMP对称多处理)计算节点。为了使第二套模型更加实用,子系统的完成时间也必须和计算节点的物理配置参数相关联,例如处理器的速度,内存的速度等等。
计算节点
下面让我们来一起关注图示2中的计算节点原型来认识相关的配置参数。图示上端的是2个处理器插槽,通过前端总线(FSB-front side bus)与内存控制中心(MCH)相连。这个内存控制中心(MCH)有四个存储信道。同时还有一个Infiniband HCA通过信道点对点串行(PCIe)连接在一起。
象千兆以太网和串行接口(SATA)硬盘之类的低速的输入输出系统都是通过芯片组中的南桥通道(South Bridge)相连接的。在图示2中,大家可以看到每个主要部件旁边都用红色标注了一个性能相关参数。这些参数详细的说明了影响性能(并非全部)的硬件的特性。它们通常也和硬件的成本直接相关。举例来说,,处理器时钟频率(fcore)在多数工作负荷状态下对性能影响巨大。根据供求交叉半导体产额曲线原理,处理器速度越快,相应成本也会更高。高速缓存存储器的体积也会对性能产生影响,它能减少主频所承载的工作负荷以提高其运算速度。处理器内核的数量(Ncores)同样会影响性能和成本。内存子系统的速度可以根据双列直插内存模块频率(fDIMM)和总线频率(fBus)进行参数化,它在工作负荷状态下也对性能产生影响。同样,电缆相互连接(interconnect fabric)的速度取决于信道点对点串行的频率。而其他一些因素,比如双列直插内存模块内存延迟(DIMM CAS Latency),存储信道的数量等都做为次要因素暂时忽略不计。
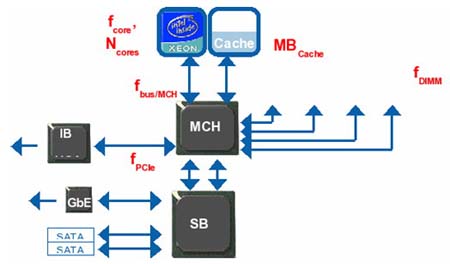
我们能使用的性能参数
在图示2中标明的6个性能参数中,我们保留四个和模型相关的参数。首先让我们先忽略信道点对点串行的频率(fPCIe),因为它主要影响的是电缆相互连接(interconnect fabric)速度的性能,这不在我们此次议题讨论范围之列。接下来让我们注意一下双列直插内存模块频率(fDIMM)和总线频率(fBus)会由于内存控制中心(MCH)而限于固定比率。在目前使用的双核系统中,这些比率最具代表性的是4:5, 1:1, 5:4。我们一般情况下只会用到其中的一个。高速缓存存储器的体积非常重要。在这个模型中我们保留这个参数。内核的数量(Ncores)和内核频率(fcore)也非常重要,保留这两个参数。
高性能计算(HPC)模型
接下来的章节我们讲解的是数学运用模型。这但对于数学运算是个挑战,让我们一起来关注这个模型。
这第二个模型的基本形式在计算机体系研究领域已经存在了很多年。A普通模式是:
(3) CPI = CPI0 + MPI * PPM
这里的CPI指的是处理器在工作负荷状态下每执行一个指令的周期。CPI0是指内核CPI,MPI I则是指在工作负荷状态下高速缓存存储器每个指令失误的次数(注释:在高性能计算领域,MPI主要用于信息传递界面,在此处主要是指处理器构造惯例),PPM是指以处理器时钟滴答声为单位对高速缓存存储器每个指令失误的次数的记录。第二和第三个方程式相互吻合。这第一个术语代表的是处理器,第二个术语代表的是内存。
通过图示我们可以直观的看到,假设每项工作下执行的P指令的工作负荷与代表处理器的频率的内核频率(每秒钟处理器运行周期的单位)再与方程式(3)相乘,就得到了方程式(4):
Tnode = (CPIo * P) * (1 / fcore) + (MPI * P) * PPM * (1 / fcore)
在这里我们要注意(CPIo * P)是以每项工作分配下处理器的运行周期为单位,对微处理器架构上运行的既定工作负荷通常是个恒量。因此我们把它命名为α。(处理器周期本身无法对时间进行测算,如果乘以内核的频率就可以得到时间的测算标准。因此Tnode在方程式(4)的右边)。 #p#page_title#e#
(MPI * P)也是同理。对于既定工作负荷和体系结构来说它也是个恒量,但它主要依赖于高速缓存存储器的体积。我们把它命名为M(MBcache)。而PPM是指访问主存的成本。对于既定的工作负荷来说,通常是个固定的数字C。PPM乘以内存频率和总线频率的比值(fcore / fBus)就从总线周期(bus cycles)转化成了处理器周期。因此PM = C * fcore / fBus。套入M(MBcache)就可以得到:
(5) Tnode = α * (1 / fcore) + M(MBcache) * (1 / fbus)
这个例子说明总线频率(bus frequency)也是个恒量,方程式(5)可以简化为方程式(6):
(6) Tnode = α * (1 / fcore) + β
在这里Tcore = α * (1 / fcore),而Tmemory = β(也就是公式2里的术语。我们把这些关键点关联在一起)。首先在模型2里,公式5和公式6都有坚实的理论基础,因为我们已经分析过它是如何从公式3推理而来(它主要应用于计算机体系理论)。其次,目前的这个模型4个硬件性能参数的3个已经包括其中。还差一个参数就是内核数量(Ncores)。
我们用直观的方式来说明内核的数量,就是假设把N个内核看做是一个网络频率上运行的一个内核,我们称之为N*fcore。那么根据公式(6)我们大致可以推算出:
(7) Tcore ~ α / (N*fcore)
Tcore~ ( α / N) * (1 / fcore )
我们也可以把它写成:
(8) αN = ( α / N)
多核处理器的第一个字母Alpha可能是单核处理器的1/N次。
通过数学推算这几乎是完全可能的。
通常情况下我们是根据系统内核和总线频率(bus frequencies)来衡量计算机系统性能,如公式(5)所阐述的。但是公式(5)的左边是时间单位--这个时间单位指的是一项工作量的完成时间。这样就能更清楚的以时间为单位说明右侧的主系统参数。同时请注意内核的时钟周期τcore(是指每次内核运行周期所需的时间)也等同于(1 / fcore)。总线时钟(bus clock)周期也是同理。
(9) Tnode = αN * τcore + M(MBcache) * τBus
这个公式的转化也给了我们一个完成时间的模型,那就是2个基本的自变量τcore和τBus呈现出直线性变化。这对我们稍后使用一个简单的棋盘式对照表对真实系统数据进行分析是有帮助的。
这个模型是如何工作的?
公式(9)中的这个模型好处何在呢?为了回答这个问题,首先让我们一起来分析两项常用的基准测试指标,Linpack(注释:指标为实数,指HPC采用高斯消元法求解一元N次稠密线性代数方程组的每秒处理次数)和Stream(注释:对单环境和多重负荷时的内存性能进行测评的基准)。我们通常会对他们进行综合的考量,这两者主要适用于商业领域。举例来说,Linpack基准测试运用的是边界元素方法,主要适用于模拟飞机雷达横截面或者模拟潜艇声学回音。Stream基准测试的核心则运用于高性能计算应用编码的方方面面。他们代表了矢量或者Level 1 BLAS。这两项基准测试指标都非常的有用因为他们从不同角度代表了高性能计算工作量频谱的两个极端。Linpack测试的是内核的计算范围,而Stream主要针对的是内存访问。这两项工作是对完成时间模型(1)一个很好的初始测试。
Linpack测试:内核范围的工作负载
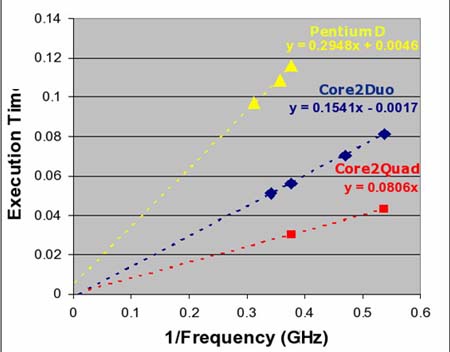
图示3向我们展示的是使用了三个不同的多核CPU(以英特尔S3000PT服务器为基础)的Linpack完成时间以及使用一个单独的CPU系统τcore的结构图。第一台CPU是英特尔公司的PentiumD(Netburst microarchitecture)双核运行多种频率可达到3.2 GHz。对于这项工作负载Linpack完成时间数据点用黄色三角标注。数据点连成的直线用黄色虚线表示。
第二台CPU是英特尔公司的酷睿双核处理器Core 2 Duo (Conroe)运行四组频率达到2.66 GHz。这个CPU的数据点和连成的直线用蓝色标注。第三台CPU是英特尔公司的酷睿四核处理器Core 2 Quad(Kentsfield)运行两组频率达到2.4 GHz。它的数据点和连成的直线用红色标注。总线频率(bus frequency)在266 MHz频率下保持恒量。结合方程式(1)和线性图可以清楚的看到β或者M(MBcache) * (1/ fBus )都为零。 #p#page_title#e#
假设Linpack能完全脱离高速缓存存储器运行而且几乎不再需要访问主存储器,那就能符合用户的需求。我们希望Tmemory或者β也能为零,这一点通过线性图已经可以确认。在这个方面模型看起来是不错的。接下来我们来分析每个数据点的变化情况。举例来说,酷睿双核处理器Core2 Duo的四个数据点连接成一条几乎完全精确的直线。在这些数据点的范围内,我们可以推断系统真实的物理性能运算与τcore成线性关系。由此我们也可以断定这个模型一个重要的方面--那就是τcore内的物理性能运算成直线型。
Stream测试:总线范围的工作负载
现在我们来关注一下这个线程的倾斜度。从方程式(9)我们知道了倾斜度与αN的值相吻合。由此我们可以推断αN = α / N 。那就是说多核并行的工作负载完成时间倾斜度与单核相比是在同等工作负载下完成时间倾斜度的1/N次。从酷睿双核处理器Core 2 Duo的直线分析,我们会发现斜面值为0.154,而C酷睿四核处理器ore 2 Quad的直线斜面值为0.0806。这是个1.91x和期望的2x的标准比。误差率大概在5%,这对于实际应用来说已经足够好了。
把Pentium D和酷睿双核处理器 Core 2 Duo的倾斜度进行对比,我们可以看到alpha (α)的另外一面。这两个处理器都是双核的,但是酷睿四核处理器Core 2 Duo每个时钟周期能执行4个SSE2指令而Pentium D只能执行两个。Linpack的工作负载能够利用SSE2指令集的完成时间单位。因此我们希望Pentium D的斜面值应该是2x酷睿双核处理器Core 2 Duo的斜面值。
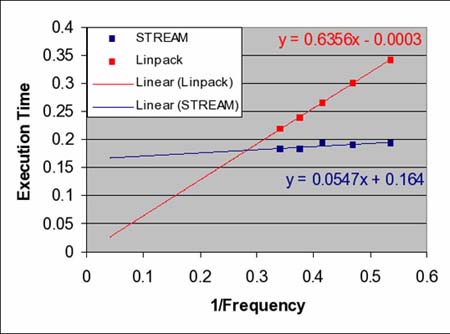
图示4展示的是在酷睿双核处理器Core 2 Duo平台系统上执行工作负载的Linpack和Stream结构图。象图示3一样,Linpack线性图有一个接近于零的测试值倾斜度比较大。Stream的线性图则正好相反。它的值相对较大,倾斜度却非常小。这种计算行为适用于总线范围内的工作负载。处理器的速度对于Stream工作负载的完成时间影响非常小。
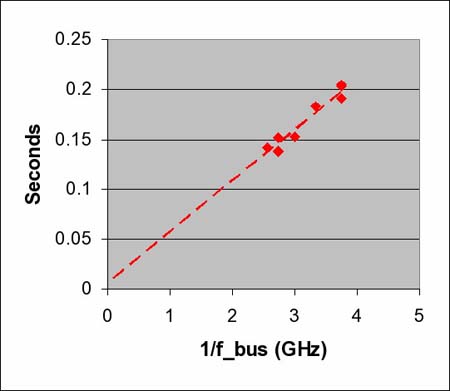
总线(bus)的频率(类似于MCH的速度和DIMM的速度)对Stream性能测试会有什么影响呢?从图示5我们可以看到前端总线频率(fBus)变化情况的影响。这些数据来自于使用酷睿双核处理器Core 2 Duo的ASUS P5B系统。总线频率(fBus)和内核频率(fcore)的比值固定在7上就简单了许多。总线频率(fBus)和双列直插内存模块频率(fDIMM)两项不同的比值分别为1:1和4:5。
图示5中的线性图说明了内存时间(Tmemory)的变化情况是和总线(bus)时钟周期τBus成正比的。我们能看到这张图示上有两处截然不同的数据点。这些点和1:1 的总线频率(fBus)比值相吻合而双列直插内存模块频率(fDIMM)比值是4:5。
更为复杂的工作负载:SPEC_CPU2000
让我们来关注一下更为复杂的工作负载,完成时间的性能计算在初始参数上仍然是直线。由此可以看出内存时间(Tmemory)还需要较大的高速缓存存储器进行缓冲存储。这个分析让我们意识到M(MBcache)的重要性。SPEC CPU2000 benchmark suite无疑是个不错的选择。这一点已经为大家所熟知。在这张图示上我们将基线编译器标记(-O2)与每一项工作负载相结合。复合工作负载的完成时间刚好是单个组件工作负载的完成时间(约等于25)。
为了测试高速缓存存储器体积对性能的影响程度,我们用"Gallatin"处理器系统来作为测试平台。这个处理器是单核Netburst体系机构的CPU,512KB L2和2MB L3高速缓存存储器。图示6向我们展示的是在处理器时钟周期变化时复合工作负载的完成时间。

深蓝色的数据点和线性图符合了激活的2MB L3高速缓存存储器的结构。淡蓝色的数据点和线性图则反映了不起作用的L3高速缓存存储器的结构情况,非常有效的把高速缓存存储器的体积精简到了512KB。这两个线性图都是平行线。斜面值是一样的,几乎没什么差别。更有趣的是我们能看到,当高速缓存存储器的体积从512KB变成2MB时,测试值的变化。内存访问和Tmemory完成的时间总计减少了1.75x。这个结论等同于增大了总线(bus)和内存频率1.75x。对于复合工作负载来说,高速缓存存储器的体积非常重要。 #p#page_title#e#
综述
现在对我们的分析做一个综述。在定性的基础上我们可以轻易的对影响高性能计算性能的因素进行罗列,比如更快的处理器,更大容量的内存,磁盘,网络等等。如果是在量化的基础上来回答这个问题,答案则有较大的不同。尤其是对于那些预算有限的用户而言,这一点是比较重要的。一台速度更快的处理器会花费更多的费用吗?在我的集群上需要PCIExpress Gen2时钟缓冲器吗?我应该购买更快的内存来获取每个计算节点上更多的内存容量吗?我如何能为用户提供更大的计算机功率(在相同的年度预算前提下)?
我们试图向大家阐明使用一个相对简单的计算节点运用模型就能很好的解释这些疑问。对于既定的工作量和计算节点,这个模型只需要简单的工具(那就是电子数据表)就能轻易的进行验证。使用这个模型还能够帮助我们解决如何选购,容量规划方面的疑问。那么回到我们最初的问题上来"如何优化高性能计算的性能?",答案是一切都取决于工作负载。


